R est mon ami-2 (**REMA-2**) -ggplot2 et réalisation de graphiques
Après notre 1er tutoriel où nous avons importé des bases de données et où nous les avons manipulées avec dplyr, nous voici maintenant à l’étape de visualiser nos données (Yeah!!!).
La visualisation est fondamentale et permet aussi d’expliquer simplement des modèles compliqués.
Comme on dit: le poids des mots, le choc des photos!
C’est un moyen intéressant de comprendre votre BD avant même de faire des statistiques.
Cette capacité de visualisation des données est UNE des principales raisons qui ont fait que je suis devenu un fan de R.
Ce paquet est PHÉNOMÉNAL car il nous permet à nous, cliniciens, de visualiser nos données et il nous permet de communiquer avec les utilisateurs de notre recherche (tant scientifiques, que producteurs, propriétaires ou intervenants divers) !!!
Ce travail est un travail en progression, donc n’hésitez pas si il y a des coquilles ou problèmes à me les signaler pour que je les corrige s.buczinski@umontreal.ca
AVERTISSEMENT: CE TUTORIEL PEUT CRÉER UNE DÉPENDENCE, SON AUTEUR REJETTE TOUTE RESPONSABILITÉ VIS À VIS D’UNE DÉPENDENCE ACCRUE AU LOGICIEL R ;-)
J’aime beaucoup ce cartoon qui illustre l’importance de la présentation et de la digestion/compréhension de vos données pour en sortir l’essence en 1 diapositive!!!

PENSEZ BIEN À VOTRE Take-home message!!!
1. Exemple de base de données et téléchargement des paquets
1.1 Paquets nécessaires pour le tutoriel
On doit télécharger des paquets d’intérêt du jour tel que présenté dans REMA-1.
library(dplyr)
library(ggplot2) # Notre paquet d'intérêt
library(readxl)
library(ggrepel)# pour indiquer des points ou données en particulier dans le graph (voir 5.5)1.2 Base de données prise en exemple
Je télécharge la même BD que dans notre document REMA-1 (NB: elle provient du site du livre de Ian Dohoo c’est la BD calf.xlsx.
Je la réimporte donc ici à titre d’exemple
veaux <- read_excel("calf.xlsx")
head(veaux, n=10)## # A tibble: 10 x 14
## case age breed sex attd dehy eye jnts post pulse resp temp umb
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1670 5 1 1 2 12 NA 0 2 NA NA 37.6 0
## 2 8124 3 2 0 1 13.5 0 0 0 130 120 39.2 0
## 3 6954 2 3 1 2 NA 1 0 2 NA NA NA 1
## 4 2737 3 4 1 1 5 0 0 0 132 40 38.6 0
## 5 5341 3 5 0 1 0 0 0 1 128 48 38.6 1
## 6 6749 10 6 0 1 5.5 0 0 0 160 48 39.6 0
## 7 3234 4 7 0 2 7 0 1 2 180 84 39 1
## 8 2325 14 8 0 1 7 0 0 0 100 20 35 0
## 9 2925 4 9 0 1 5 0 0 0 150 52 39.5 0
## 10 7108 8 1 0 2 10 0 0 2 120 68 37.8 0
## # ... with 1 more variable: sepsis <dbl>J’ai donc cette BD qui va me servir d’illustration pour la suite (C’est juste pour illustrer mon point donc libre à vous de laisser libre court à votre imagination avec votre propre base de données!!!)
2 Bases de fonctionnement du paquet ggplot2
2.1 spécification de la BD et de la structure du graphique (abscisses et ordonnées)
Le paquet ggplot2 (pour grammar of graphic plot) a été mis en place afin de pouvoir s’intégrer à la suite tidyverse. Il fonctionne toujours de la façon suivante.
Dans un premier temps on utilise un statement de base qui regroupe :
La base de données d’intérêt data=
Le mapping du graph qui illustre l’esthétisme de ce que l’on veut en x (abscisses) et y (ordonnées), voir des ajouts ex coloriser une 3ème variable pour faire ressortir une éventuelle différence de y=f(x) selon la 3ème variable…=> mapping=aes() )
Mais commençons simplement dans un premier temps.
Je veux par exemple voir la relation entre la déshydratation dehy (en x) et la fréquence cardiaque pulse (y)…
Notez bien que je ne fais pas de test statistique ici (je veux juste voir mes données)…
g <- ggplot(data=veaux, mapping=aes(x=dehy, y=pulse)) #ici je crée juste la base de mon graph qui va référer en tout temps à la définition de mes x et y
#NB: je vous ai écrit la commande au complet mais on aurait pu écrire aussi
#g <- ggplot(veaux, aes((x=dehy, y=pulse))
# la portion data= et mapping= sont non essentielles mais je vous l'ai écrite au long la première fois afin que vous ayez la portion complète du codeNotez que lorsque j’exécute ce code, rien ne se passe (pas de panique!).
J’ai juste créé un objet g qui contient les bases de tout graphique subséquent… (g<-)
Je dois maintenant exécuter la commande d’affichage de cet objet en exécutant g (run)
g
Ici je vois le résultat…. J’ai juste créé mon plan cartésien…
Maintenant le fun commence (yeah!!!).
Les fonctions de ggplot2 fonctionnent ensuite avec des geom_. Les geom_ sont des spécifications graphiques que R va utiliser pour représenter ce que l’on veut.
Comment faire pour savoir ce que l’on va obtenir?
Il faut savoir quel geom_ utiliser…
Je vous réfère à la cheatsheet ggplot2 pour les infos sur les geom mais aussi à la galerie des graphiques obtenus sur R pour des notions plus exhaustives. Le tout est d’avoir son idée et des bases de fonctionnement du paquet et ensuite on peut se débrouiller.
Moi, je me contente donc de donner des grands principes de préparation d’un code avec ggplot. Après cela, comme dans tous les domaines, il vous faudra regarder par les essais erreurs.
Un conseil: le but du tutoriel n’est pas de vous dire quelle représentation graphique vous devez utiliser. Ce qui est important est que vous preniez le temps de bien y penser et de voir le message que vous voulez passer à votre auditoire
Un livre fascinant que je conseillerais est de Kieran Healy: Data Visualization A practical introduction il est en ligne sur la page suivante. En plus des concepts pour faire un bon graphique. Il explique superbement le fonctionnement de ggplot2 et est donc un incontournable pour toute personne qui veut creuser un peu plus en détails!!

Livre de Kieran Healy: Un incontournable!!!
2.2 Ajout des geom_ et premier(s) graphique(s)
On a toujours en banque notre objet g. Nous allons nous en servir pour construire nos graphs selon nos envies… (On ajoute juste des couches pour spécifier comment nous voulons représenter nos données). Le fait de stocker g qui contient les informations primordiales est (pour vous) de pouvoir ajouter des couches de graphs sans retaper tout la 1ère structure du code (data et mapping).
On va commencer simplement.
On peut vouloir par exemple représenter le tout sur un nuage de points (équivalent de PROC SGPLOT SCATTER PLOT SUR SAS…)
Chaque type de graphique est utilisé en appelant la géométrie qui lui est associée. Par exemple si vous regardez dans la cheatsheet ggplot2 vous verrez que si vous voulez visualiser un graphique avec 2 variables continues vous avez différentes options parmi lesquelles la visualisation individuelle de vos données sous forme de point: geom_point().
Cette fonction (geom_) est la base de ggplot. Une fois que la structure du graph est décidée (relation que vous voulez voir spécifiée dans les arguments ggplot) vous pouvez commencer votre visualisation en ajoutant un ou plusieurs geom_ avec le signe +.
Allons-y bien basique pour commencer:
g+geom_point()## Warning: Removed 17 rows containing missing values (geom_point).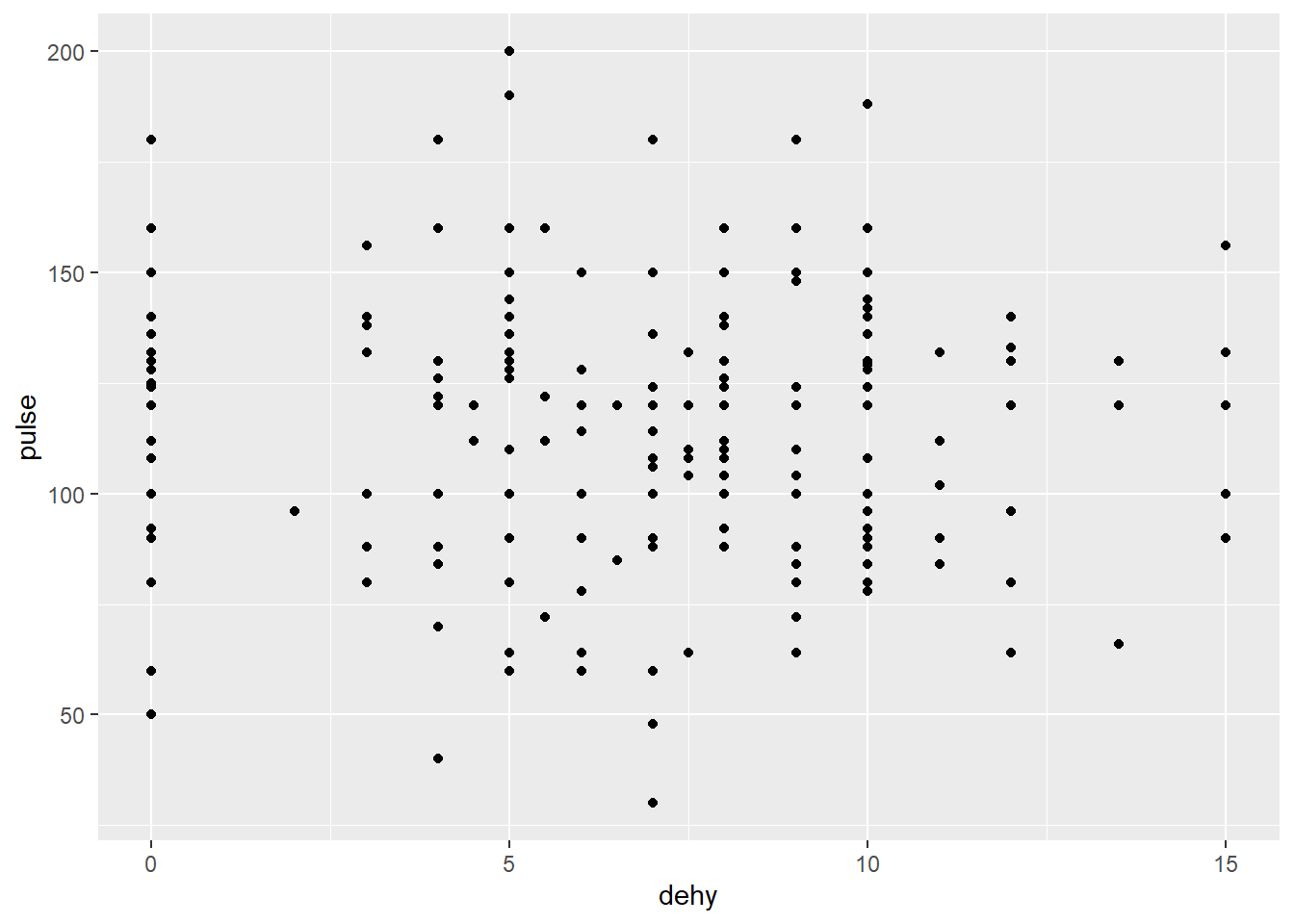
Et c’est tout, vous avez fait votre premier graphique avec ggplot…
BRAVO!!! (Je savais que vous en étiez capable)
Si vous avez compris ces 3 principes (data, structures avec le mapping et geom_graph()) vos progrès vont être exponentiels: je vous le garantis!!!
Vous avez juste utilisé g et mentionné que vous vouliez faire un graphique en point…
Notez le message d’alerte mentionné ici (warning) qui est associé à un message qu’envoie le logiciel afin de vous spécifier une information (ici on a des données manquantes). Le warning n’est pas un message d’erreur mais juste une info que R veut vous partager. C’est cependant important de bien les regarder pour s’assurer que l’on est bien au courant et que cela n’impacte pas notre output.
Par la suite je vais éliminer les données manquantes de mon code pour des raisons pratiques…
nrow(veaux)## [1] 254veaux <- na.omit(veaux)
nrow(veaux)## [1] 213J’avais au départ 254 lignes de données. Maintenant j’en ai 213 après avoir retiré les données manquantes. Ca prendrait un tutoriel complet sur la gestion des données manquantes (j’y pense sérieusement)…
Imaginez que maintenant vous vouliez changer l’aspect visuel. Les points c’est bien mais pourquoi pas mettre cela sous la forme de diagramme de chaleur qui représente la densité de points…
g+geom_density2d() #voir les données en densité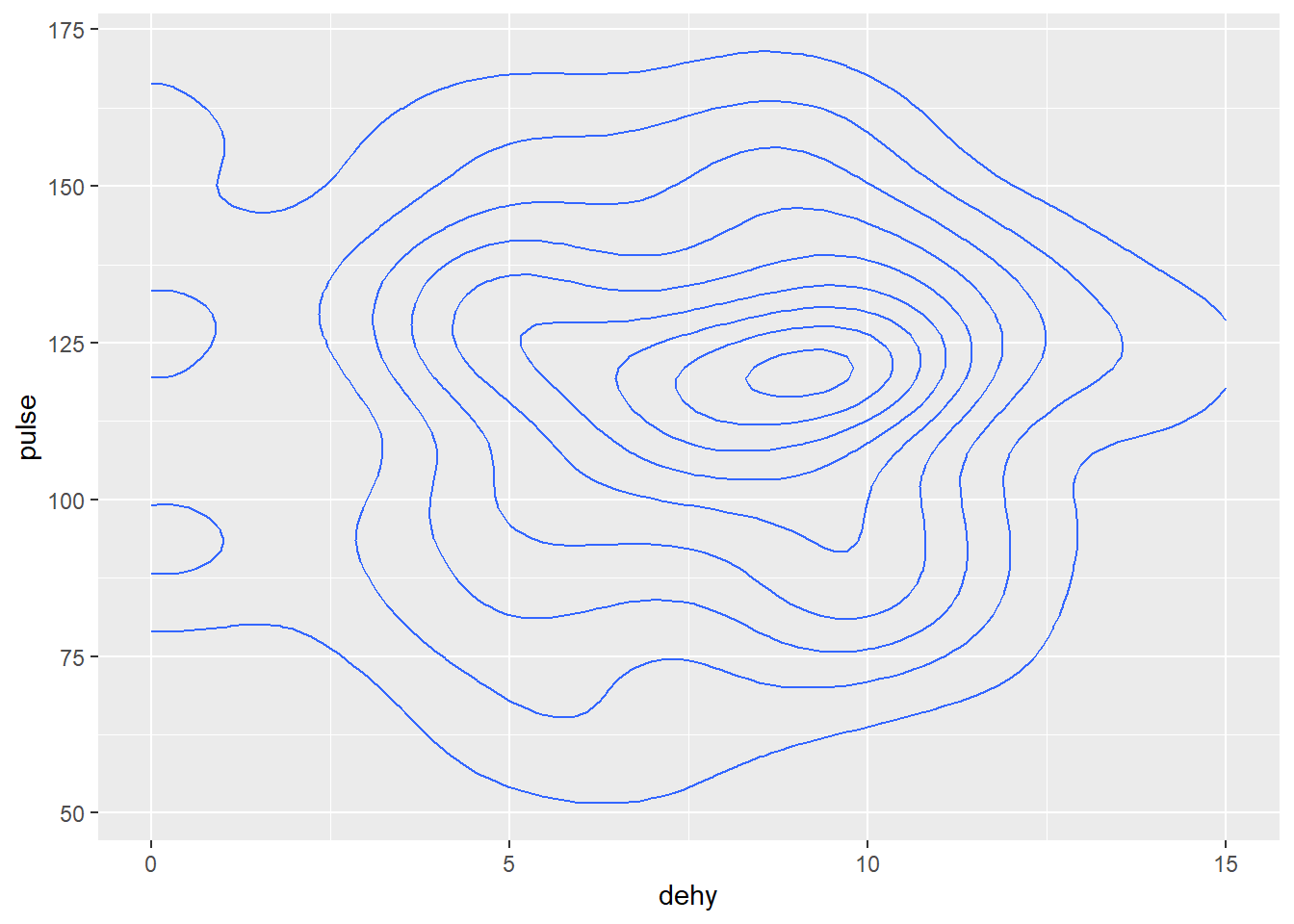
g+geom_hex() #voir les données aussi sous forme de densité dans des hexagones...
#voir toutes les possibilités de représenter des graphs avec 2 variables continues...OK vous comprenez le principe.
Pour l’instant vous ajoutez +geom_voulu() avec votre type de geom spécifique. Notez les () qui suivent votre geom_. En effet, même si je vous montre la base, vous pouvez bien sur mettre des options spécifiques dans votre geom_x().
Par exemple je peux facilement changer la forme des points, leur taille, leur couleur ou tout autre spécificité de mon choix. Si vous ne vous rappelez pas les arguments à utiliser (c’est normal de ne pas les connaitre par coeur), utilisez dans la console ?geom_xxx(). Vous allez avoir accès à toutes les explications pour ajouter ou modifier les défauts.
Si le geom_ n’est pas supporté par votre structure de données (ex: si je tapais g+geom_density() j’aurai un message d’erreur car pour avoir une densité je ne dois pas avoir de y dans ma commande ggplot() )…
2.2.1 Changer les couleurs des points
g+geom_point(color="red") # 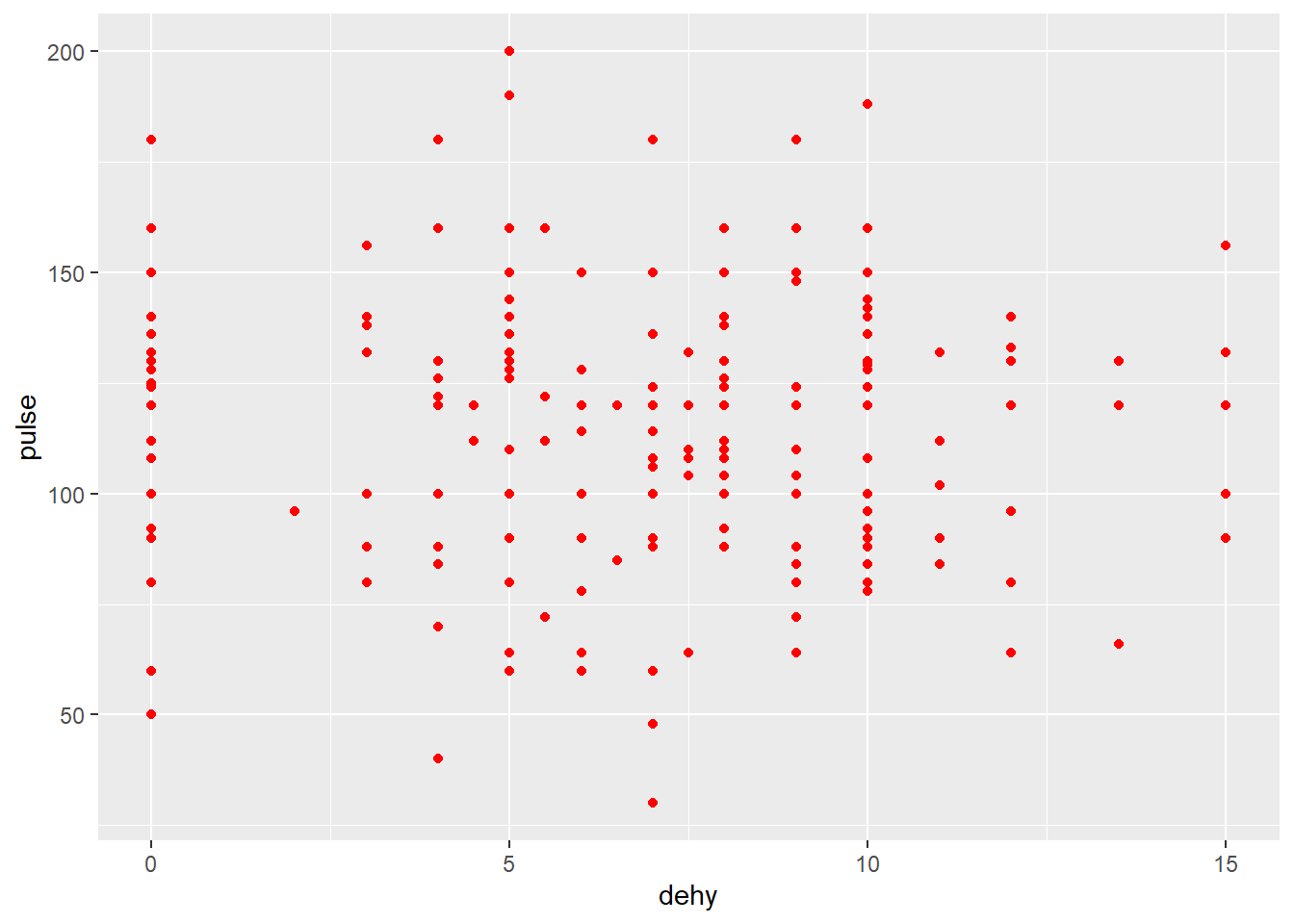
2.2.2 Changer la taille et la forme des points
g+geom_point(shape=8, alpha=0.2, colour="darkblue")
La forme des points est l’argument shape : l’ensemble des formes est dispo sur cette page.
L’argument alpha entre 1 et 0 spécifie la transparence. Plus c’est proche de 0, plus c’est transparent. C’est un moyen de voir la superposition des données quand on en a beaucoup. Ici on peut voir que certaines formes sont plus foncées. Ce qui signifie que plusieurs données identiques se superposent.
Pour les couleurs, sky is the limit toutes les couleurs sont codées de façon standard RGB avec un code du type ##…. ou sous une forme plus littéraire.
Note: si vous n’êtes pas un fan de la tranparence, pour voir des données superposées avec les mêmes (x,y), vous pouvez utiliser le geom_jitter()
Ce que fait ce geom_point() particulier est lorsque 2 points on la même coordonnées (x,y) d’ajouter une erreur aléatoire afin qu’ils ne se superposent pas. C’est très intéressant pour ce types de données (NB: la transparence alpha donne une information similaire): cela permet de visualiser la superposition que le geom_point() sans transparence ne permet pas…
g +geom_point(colour="blue") 
#comparer à
g +geom_jitter(colour="blue") 
TAKEHOME MESSAGE: VOUS VOYEZ QUE LES POSSIBILITÉS SONT GRANDES (ET ON N’EST QUE SUR UN SIMPLE GEOM_POINT() DONC JE VOUS LAISSE IMAGINER AVEC D’AUTRES GEOM)
PASSEZ DU TEMPS SUR CETTE PREMIERE ÉTAPE. ENSUITE ON VA COMMENCER À VOIR DES CHOSES ENCORE PLUS EXTRAORDINAIRES!!!
2.2.3 Ajout de plusieurs geom_ dans un même graphique
Ce qu’il y a de merveilleux est qu’à partir du même objet qui matérialise le squelette de ce que vous voulez voir (ici notre g), vous ajoutez des couches de graphique supplémentaires uniquement avec le signe + (rien de très compliqué…).
2.2.3.1 Des points et une ligne de tendance pour commencer
On a vu ici que nous avions un nuage de point mais c’est difficile de voir un patron se dégager. On peut donc demander une ligne de tendance avec la fonction geom_smooth() qui va aider à visualiser cette tendance. Différents arguments existent (comme tout geom_ et on peut spécifier la méthode de tracé de la ligne, lm pour linear model, loess pour le loess estimate…). Je vous renvoie aux méthodes complètes (on peut aussi spécifier directement d’autres formules d’approximation).
g+geom_point() + geom_smooth(method="lm") # ici je précise que je veux une méthode de modèle linéaire pour obtenir le visuel global de la droite...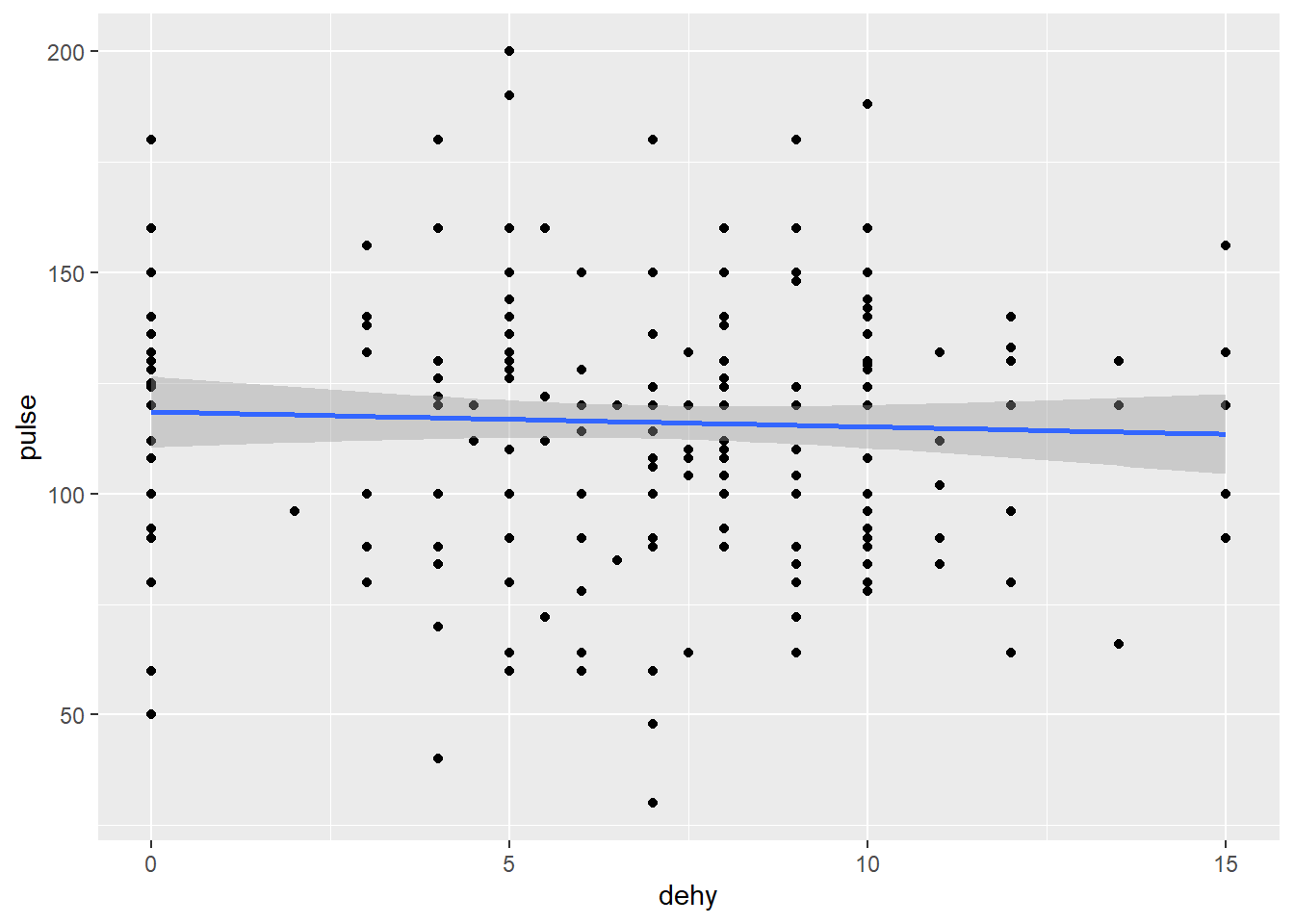
g+geom_point() + geom_smooth(method="loess", se=FALSE) #ici je veut la méthode loess pour avoir une courbe non linéaire mais suivant la méthode loess
#je spécifie aussi que je ne veut pas la bande matérialisant l'incertitude (standard error)2.2.3.2 Personnalisation des couleurs et remplissage des geom_
Je peux bien sûr moduler l’apparence selon mes gouts du jour…
Cela n’a pas de limites…
g+geom_point(color="#39568CFF") + geom_smooth(method="lm", color="#FDE725FF", fill="#481587FF")+
theme_bw()
#ici j'ai spécifié la couleur de mes points avec (un mauve...). Moi je suis un fan des couleurs utilisées dans un paquet de R `viridis` donc j'utilise souvent ces couleurs comme celle qui est indiquée ci-dessus pour les points.
#dans le geom_smooth() j'ai spécifié la couleur de la ligne (jaune de viridis) et le remplissage de la marge d'erreur (mauve), par défaut cette marge a un certain niveau de transparence...2.2.4 Faire apparaître une autre variable…
On pourrait en même temps que nous mettons en évidence ce graphique, intégrer une autre dimension, par exemple en essayant de visualiser l’âge des veaux selon leur pulse et dehy.
Rien de plus simple
#essayez ce code => il ne marche pas!!!
g+geom_point(fill=age) Je ne peux pas spécifier la variable age dans mon geom_ car elle n’est pas spécifiée dans ma commande initiale de ggplot() (avouez, je vous ai bien eus!). Je dois donc spécifier que je vais en plus de x et y, demander une autre variable age. Je vais dans un premier temps spécifier que je veux que cette variable soit indiquée en couleur (c’est un 3ème critère de mapping de mon graph).
ggplot(data=veaux, mapping=aes(x=dehy, y=pulse, color=age))+geom_point() 
J’aurai pu aussi demander à ce que le point soit de taille proportionnelle à l’âge…
#ici je mentionne l`age comme variable qui sera représentée par la taille du point et je veux que mes points soient rouges
ggplot(data=veaux, mapping=aes(x=dehy, y=pulse, size=age))+geom_point(color="red") 
#ensuite je veux qu'en plus de l'age, la couleur soit fonction de la variable respi. Ici il ne faut pas que je spécifie une couleur unique puisque c'est le gradient de couleur qui va être proportionnel à la respi...
ggplot(data=veaux, mapping=aes(x=dehy, y=pulse, size=age, color=resp))+geom_point() 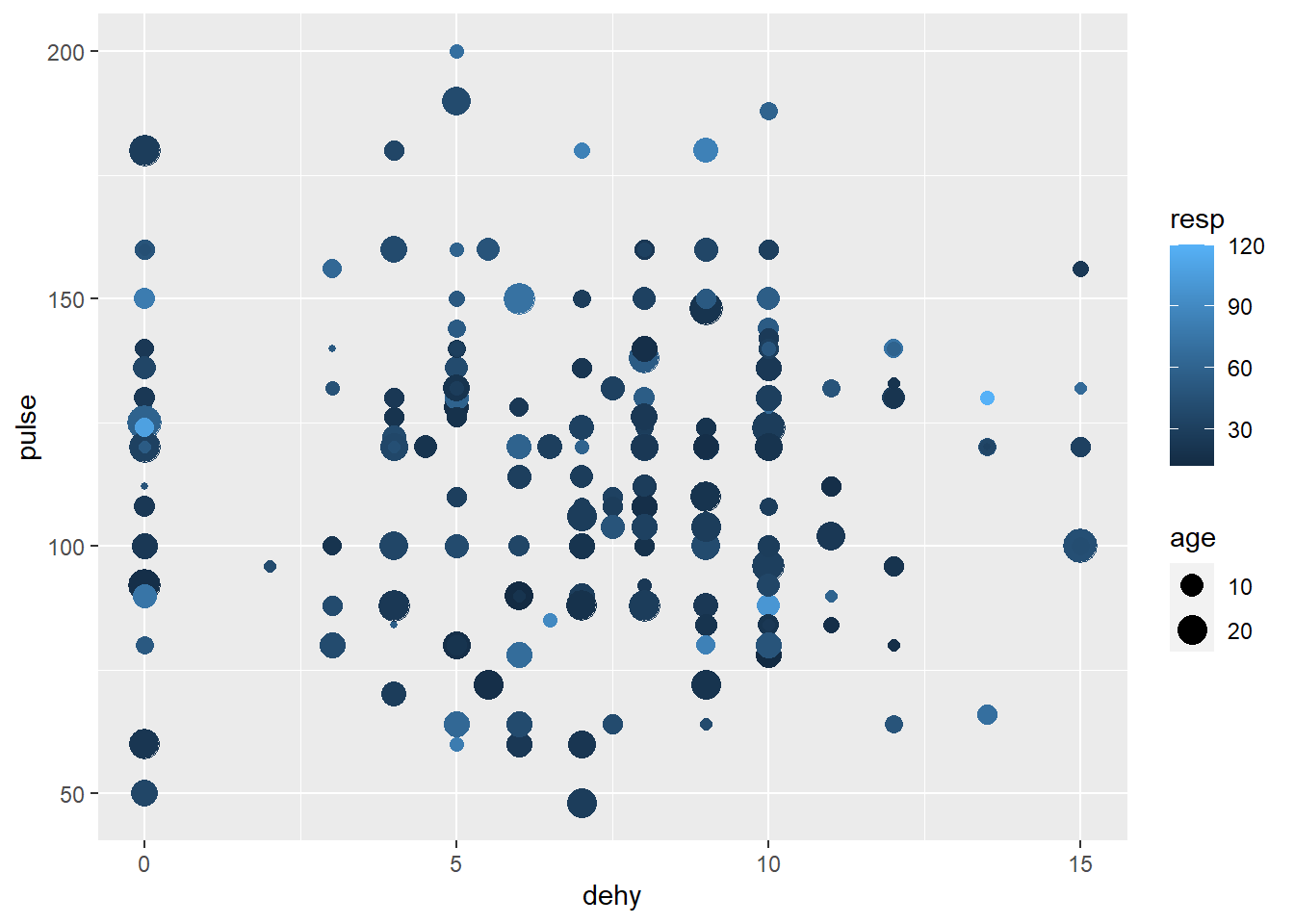
Ici en gris ce sont les point avec les infos de dehy, pulse et age mais pour lesquelles resp est une NA.
3. Représentation de la distribution d’une variable
3.1 Exemple simple : représentation de la variable pulse
Je voulais commencer par un exemple avec 2 variables (1 en abscisse et 1 en ordonnée) afin de rentrer dans le vif du sujet mais souvent on part de plus simple avec la distribution d’une variable…
Comme précédemment, je stocke les informations d’intérêt pour déterminer les éléments de mon graphique: appelons cet objet univar_pulse (je me surpasse en terme d’originalité…).
univar_pulse <- ggplot(veaux, aes(x=pulse)) #ici comme mentionné plus tôt, j'ai spécifié :data=veaux, mapping=aes(x=pulse) en allant à l'essentiel
univar_pulse
Comme précédemment la dernière ligne de ma commande ne sert à rien si ce n’est à spécifier les cadres de mon graph (ici juste les abscisses sont spécifiées…).
Que manque-t-il pour avoir un merveilleux graph???
UN GEOM_ BIEN SUR!!!
Admettons que je veuille voir un histogramme (je commence tranquillement)
univar_pulse+ geom_histogram()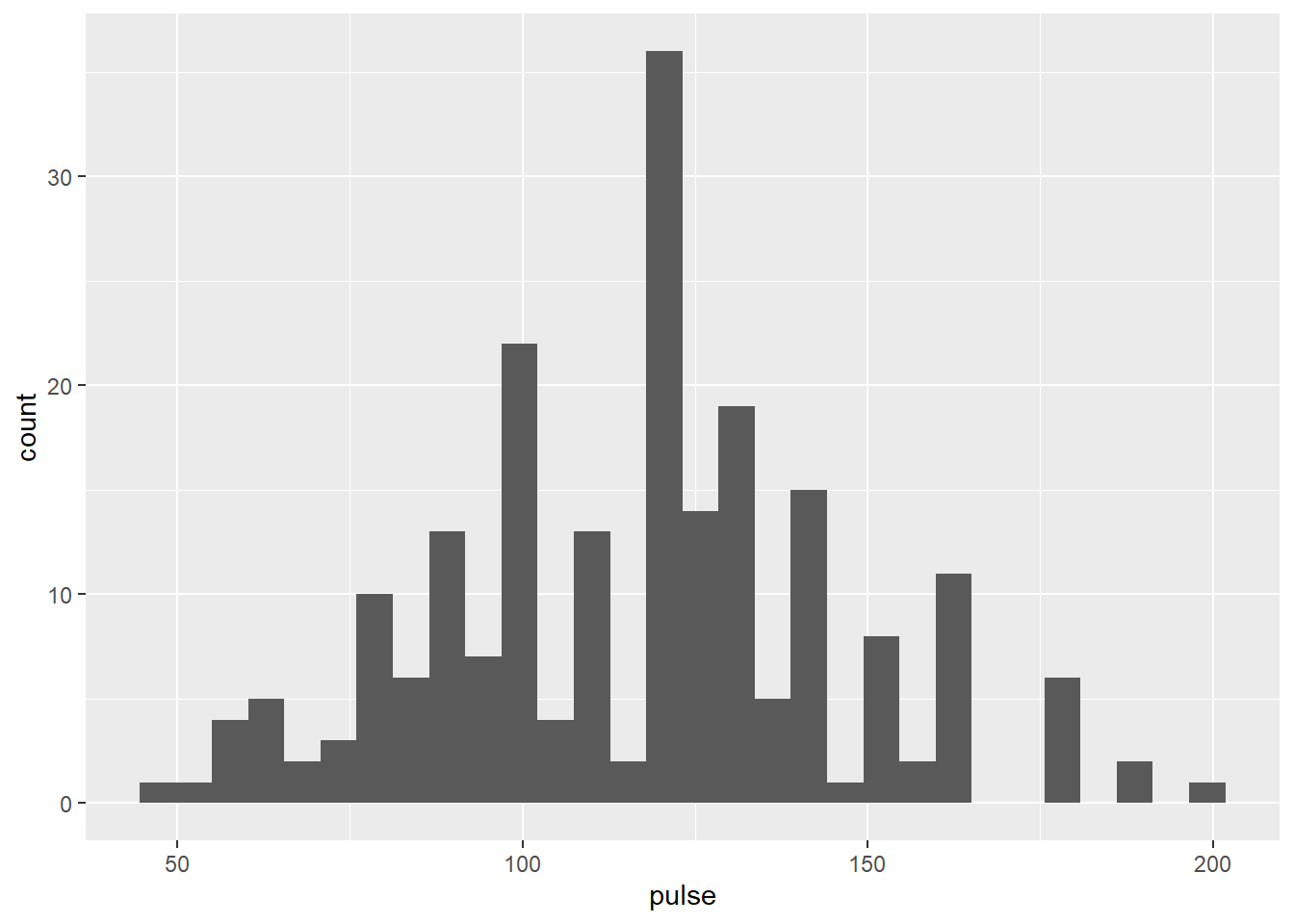
Pour la première fois on voit apparaître ce que fait notre gentil R sans qu’on le voit nécessairement. Pour chaque geom_ il utilise ou calcule une certaine stat (ici il compte les veaux (en ordonnées apparait le terme count) par strate ou bin de l’histogramme). Par défaut il utilise le nombre de bin de défaut du geom_ (ici 30) ce que l’on peut bien sur modifier…. avec la commande bins= …
univar_pulse+ geom_histogram(bins = 10)+ggtitle("10 intervalles ")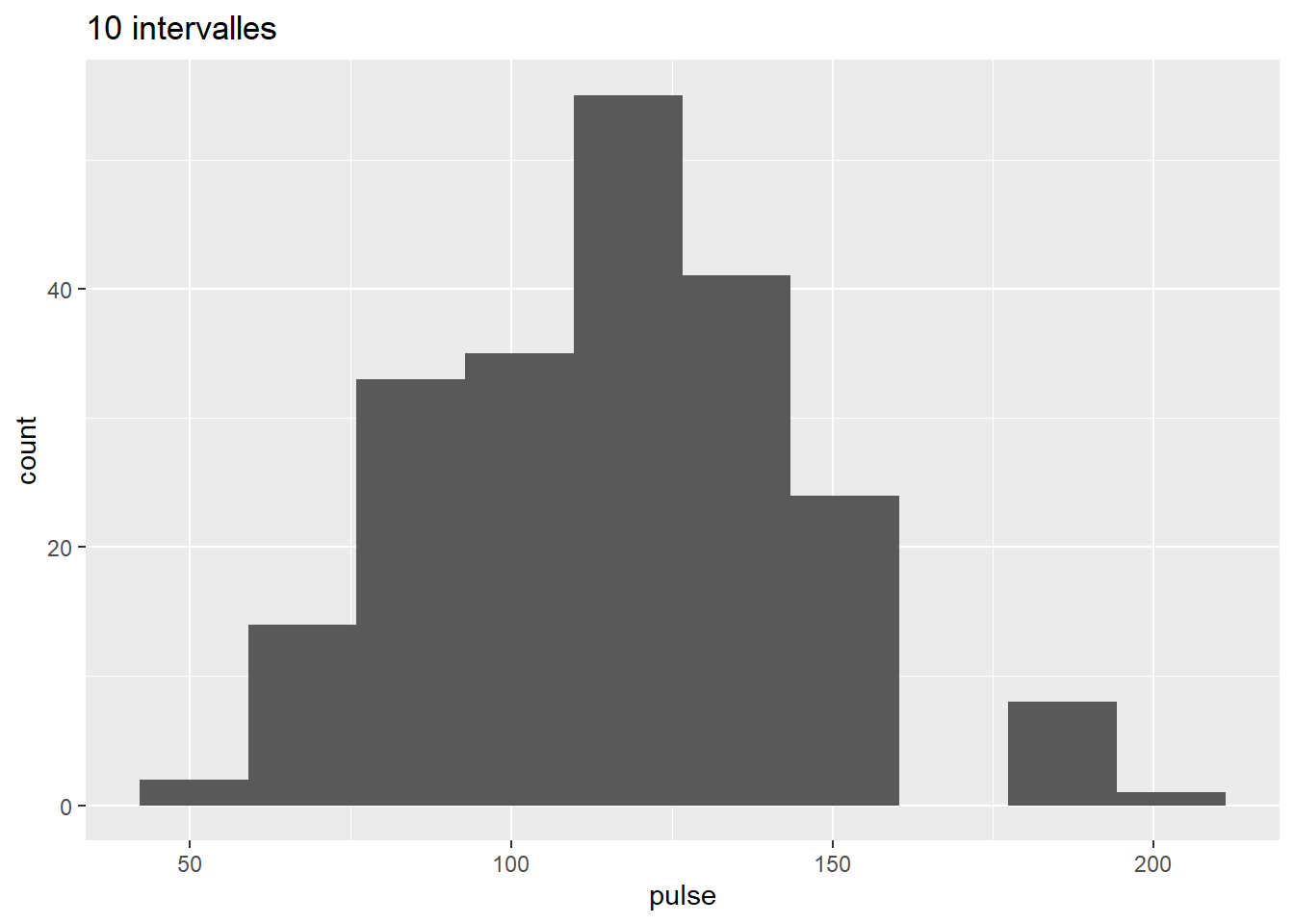
#notez ici que je vous ai introduit la fonction `ggtitle` puisque ce sont une série de graphs similaires afin de noter les différence. Vous le voyez cette fonction est juste pour mettre un titre à votre graph. Encore un truc sympa et facile!!!
# je pourrais aussi spécifier un argument sur la taille (intervalle des bins)
univar_pulse+ geom_histogram(binwidth = 50) + ggtitle("étendue d'intervalle fixée à 50")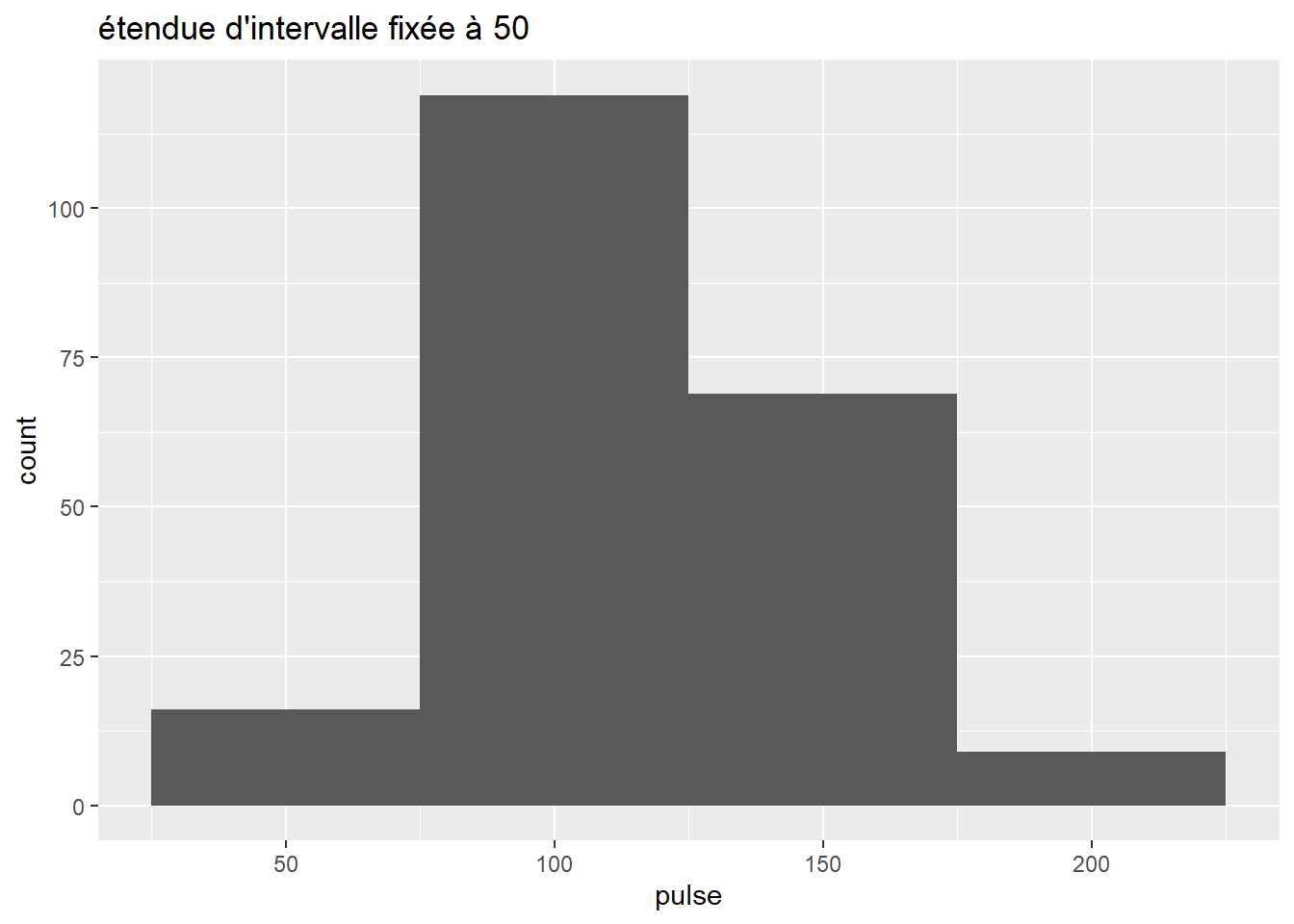
#ici j'ai spécifié que je partais avec des regroupements par 50 (plage de x regroupée)
#enfin je peux manuellement préciser l'intervalle des bins en utilisant l'argument `breaks` et une combinaison de chiffres (ici 5 bornes définissant 4 intervalles...)
univar_pulse+ geom_histogram(breaks=c(0,80, 120, 160, 200)) + ggtitle("bornes des intervalles spécifiées manuellement avec breaks=c(,,,)")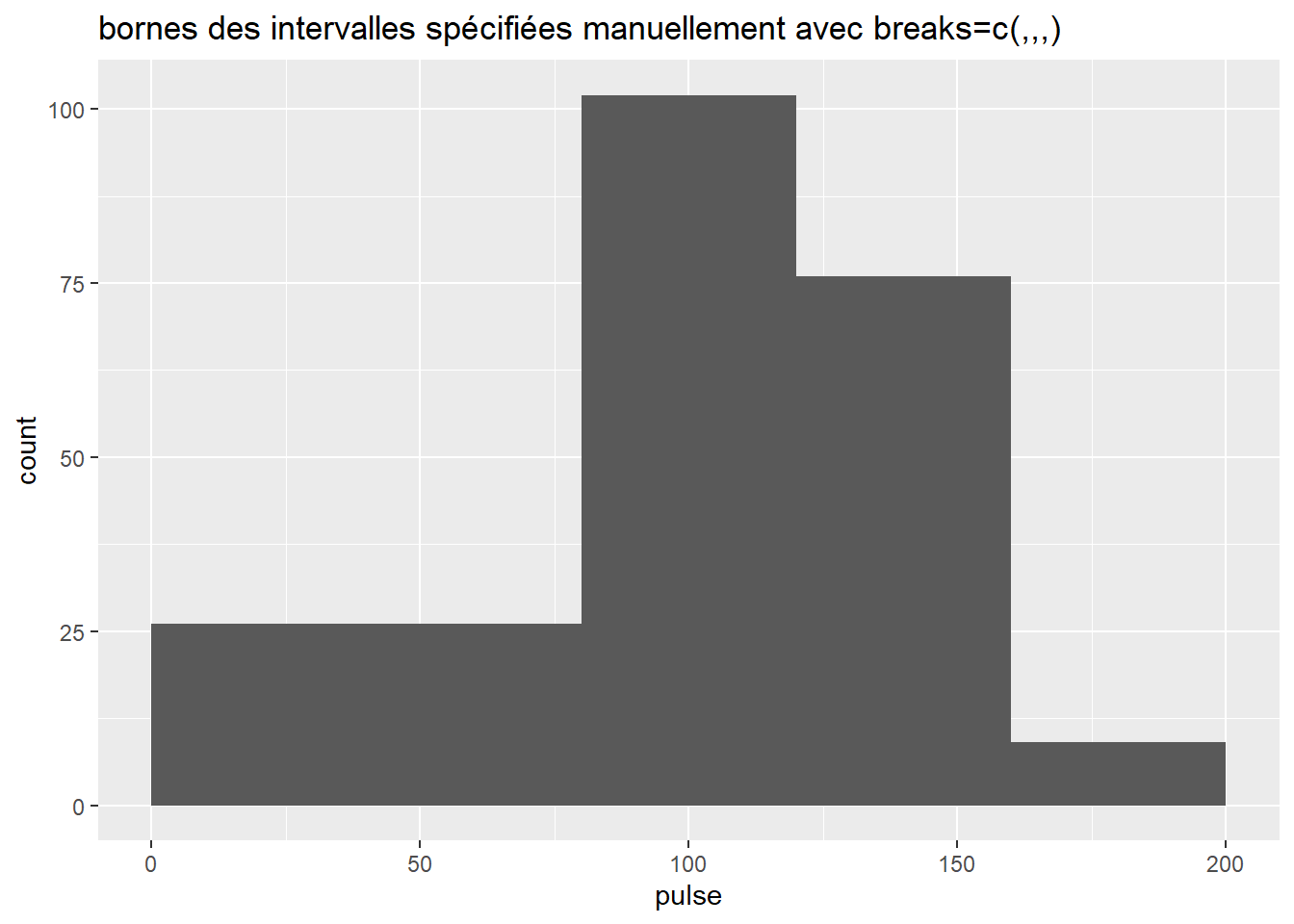
Je vous renvoie aux arguments disponibles dans le site de ggplot2.
Maintenant j’aurai pu aussi vouloir représenter la densité de ma distribution (et oui un autre geom_ est à la rescousse…)
univar_pulse + geom_density()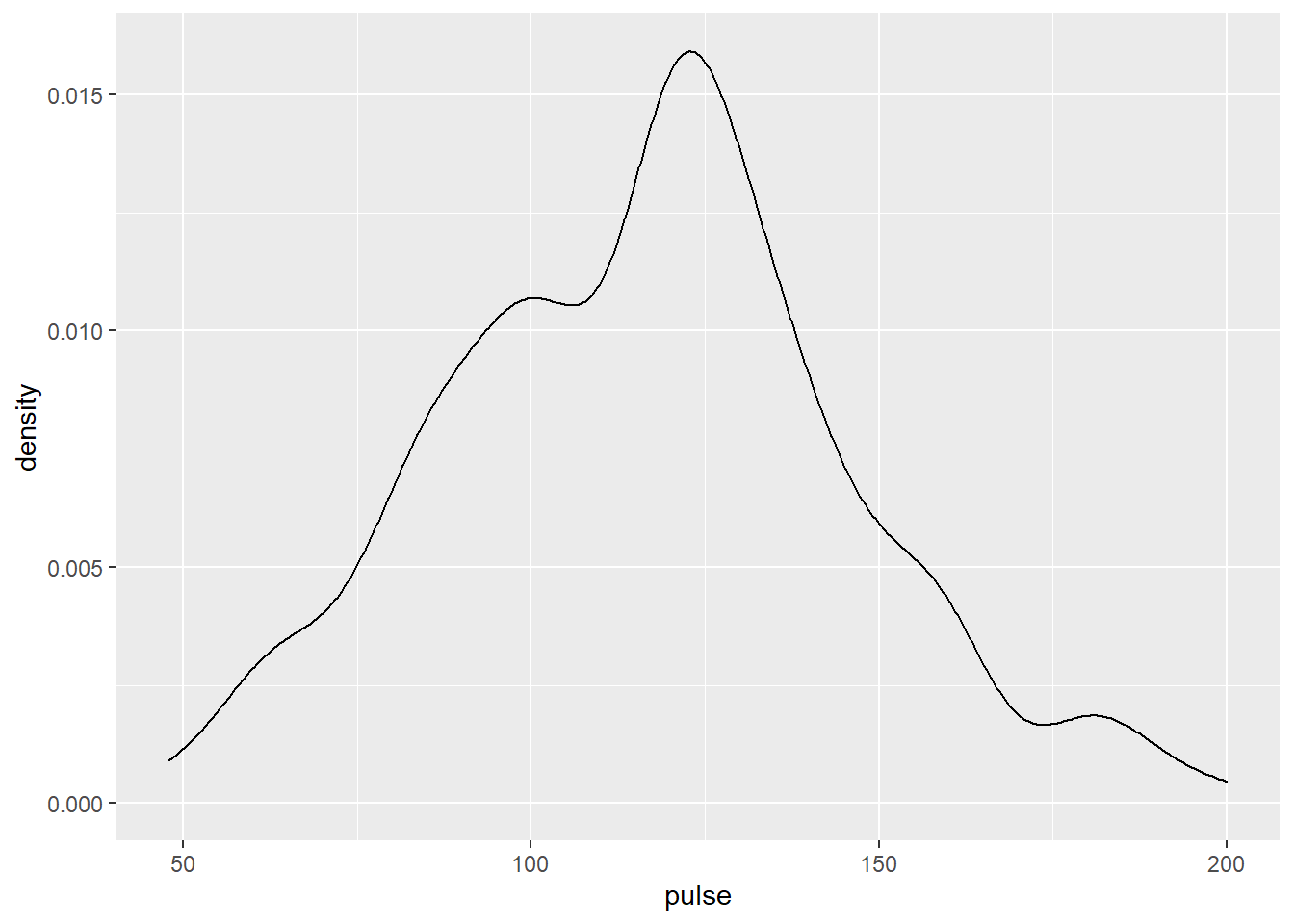
univar_pulse + geom_density()+
geom_vline(xintercept = 100, linetype="dotted",
color = "blue", size=1.5) + ggtitle("Ajout d'une ligne verticale geom_vline dotted")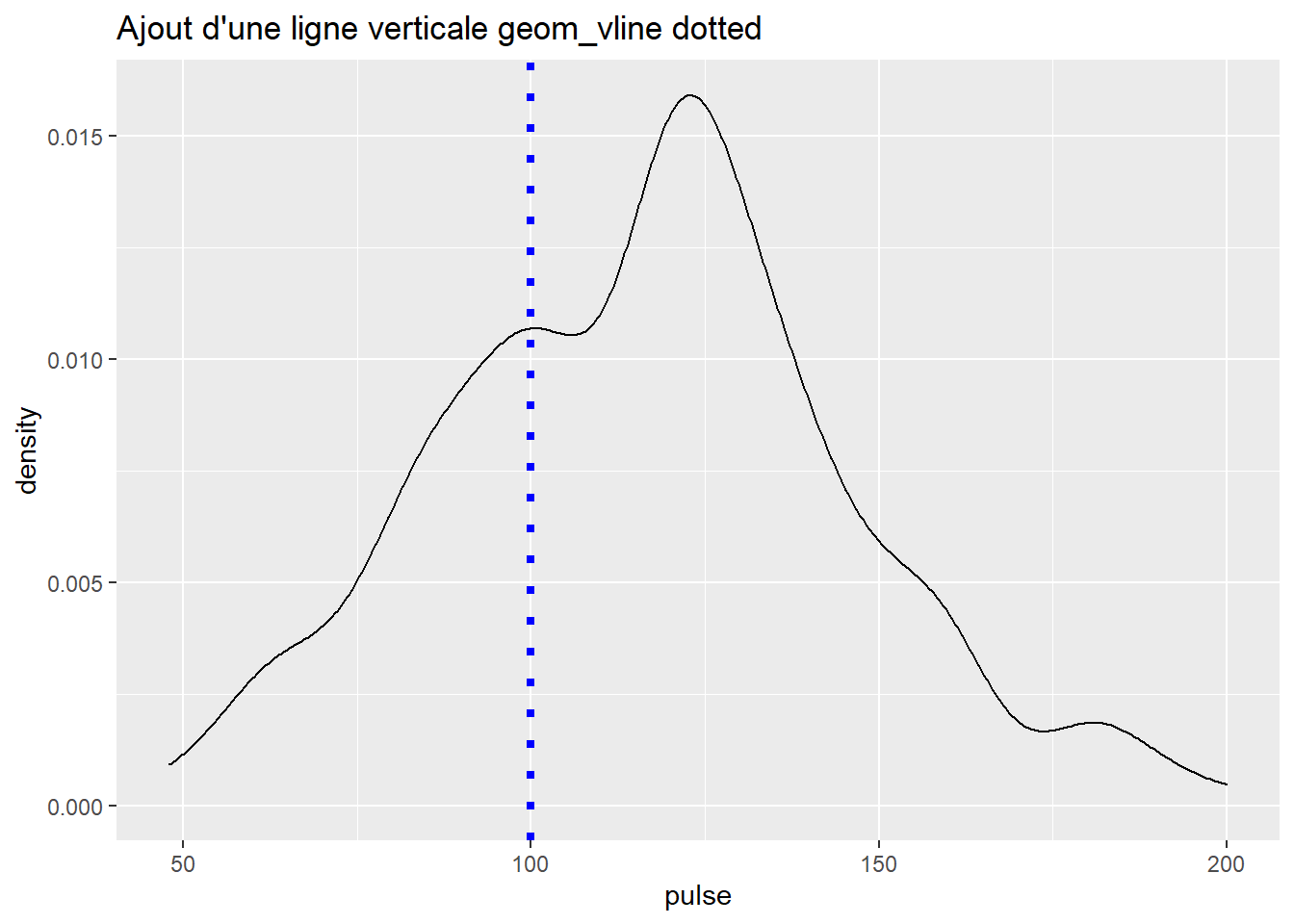
#j'ajoute une ligne verticale bleue pointillée de taille 1.5 partant à x=100.
#Notez que si je veux une ligne horizontale il suffit que j'utilise geom_hline (original!)
univar_pulse + geom_density()+
geom_hline(yintercept = 0.01, linetype="dashed",
color = "red", size=1.5) + ggtitle("Ajout d'une ligne horizontale geom_hline dashed")
Notez une chose, ici on voit que la stat associée à geom_density() est différente de celle de geom_bar(). Donc vous ne pourrez pas directement superposer ces 2 geom_ dans le même graphique…
En revanche rien ne m’empêche de superposer des graphiques se basant sur des statistiques comparables…
univar_pulse + geom_histogram(bins=15, color="darkblue", fill="yellow" ,alpha=0.5) + geom_dotplot(fill="red", color="black", alpha=0.3)
Bon ce graphe est loin d’être beau mais c’est pour que vous compreniez le principe…
Je pourrais aussi ajouter une courbe polygone sur mon histogramme associée à geom_freqpoly. Pour l’instant je n’ai pas encore trouvé de types de données où cette représentation apporte de quoi mais bon…
univar_pulse + geom_histogram(bins=15, color="orange", fill="yellow" ,alpha=0.3) + geom_freqpoly(color="black") +
theme_classic() # pour faire un arrière plan moins chargé
Vous pouvez explorer les possibilités par vous même car je ne pourrais pas tout mettre ici…
3.2 Représenter une variable continue stratifiée par une autre variable
Pour la cause ici je essayer de créer de regarder la répartition de pulse en fonction de la déshydratation mais en essayant de différencier les animaux en 2 catégories : déshydratés ou pas en fonction de dehy .
Je regarde d’abort sa médiane qui va me servir à couper ma BD (encore une fois c’est juste une illustration du principe…)
median(veaux$dehy, na.rm = TRUE)## [1] 7.5ggplot(veaux, aes(dehy))+geom_histogram(color="blue", fill="blue", alpha=0.2, bins=8) +
geom_vline(xintercept=7.5, color="black") #juste pour visualiser...
#maintenant je vais créer ma variable catégorique deshydratation dichotomique...
veaux1 <- veaux %>% mutate(deshydratation=factor(case_when(is.na(dehy)~"Pas d'info", dehy<7.5~"Non", TRUE~"Oui")))
class(veaux1$deshydratation)## [1] "factor"3.2.1 Box-plot sur R (geom_boxplot)
Maintenant je vais regarder la FC en fonction de ma déshydratation catégorisée par un bon vieux box-plot… (geom_boxplot).
La commande de base est très simple encore une fois. On peut modifier cela avec un paquet d’options toutes plus originales les unes que les autres (voir site stdha). Allez sur ce lien, il est vraiment trop bien fait!!!
ggplot(veaux1, aes(x=deshydratation, y=pulse))+geom_boxplot()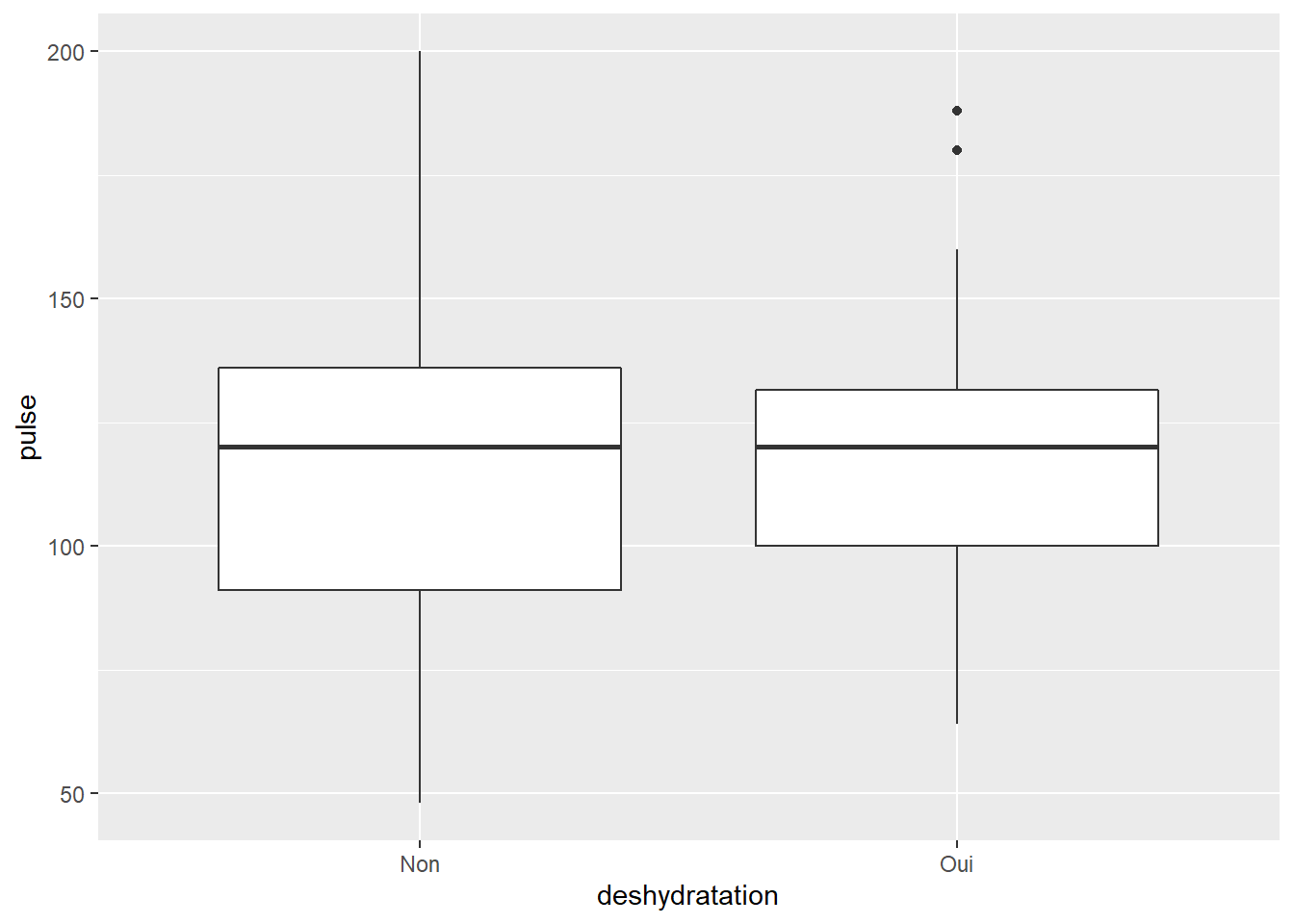
Bon mais on peut faire mieux, par exemple ajouter en plus les points de mes données
ggplot(veaux1, aes(x=deshydratation, y=pulse))+geom_boxplot() +
geom_point(color="blue", alpha=0.3)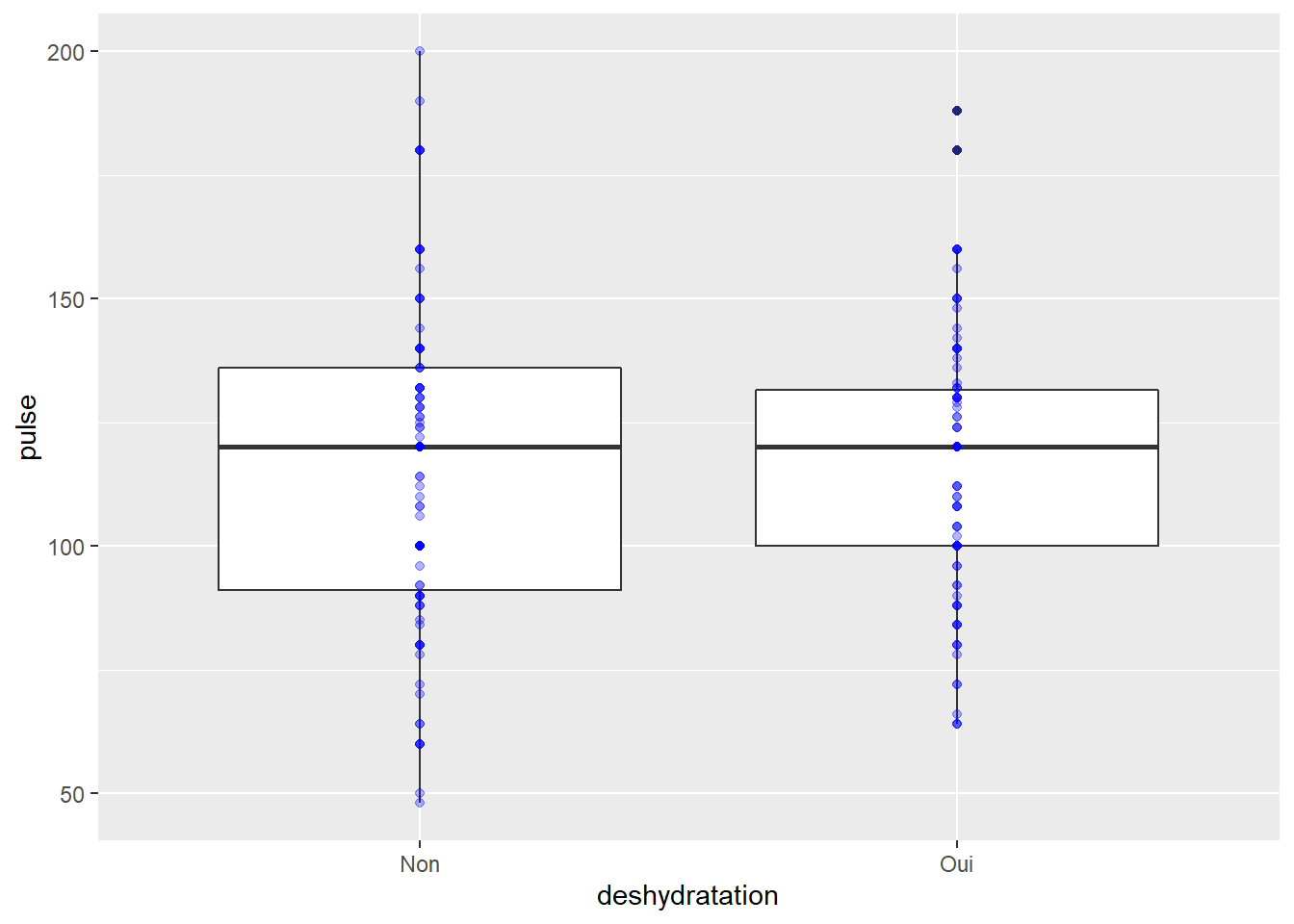
Pas très informatif… car les points se superposent et cela n’ajoute donc rien à mon visuel…
Essayons le geom_jitter.
ggplot(veaux1, aes(x=deshydratation, y=pulse))+geom_boxplot() +
geom_jitter(color="blue", alpha=0.3) # j'ajoute les points en plus sans superposition (vous pouvez l'inactiver (n'oubliez pas d'enlever le + sinon vous aurez une erreur))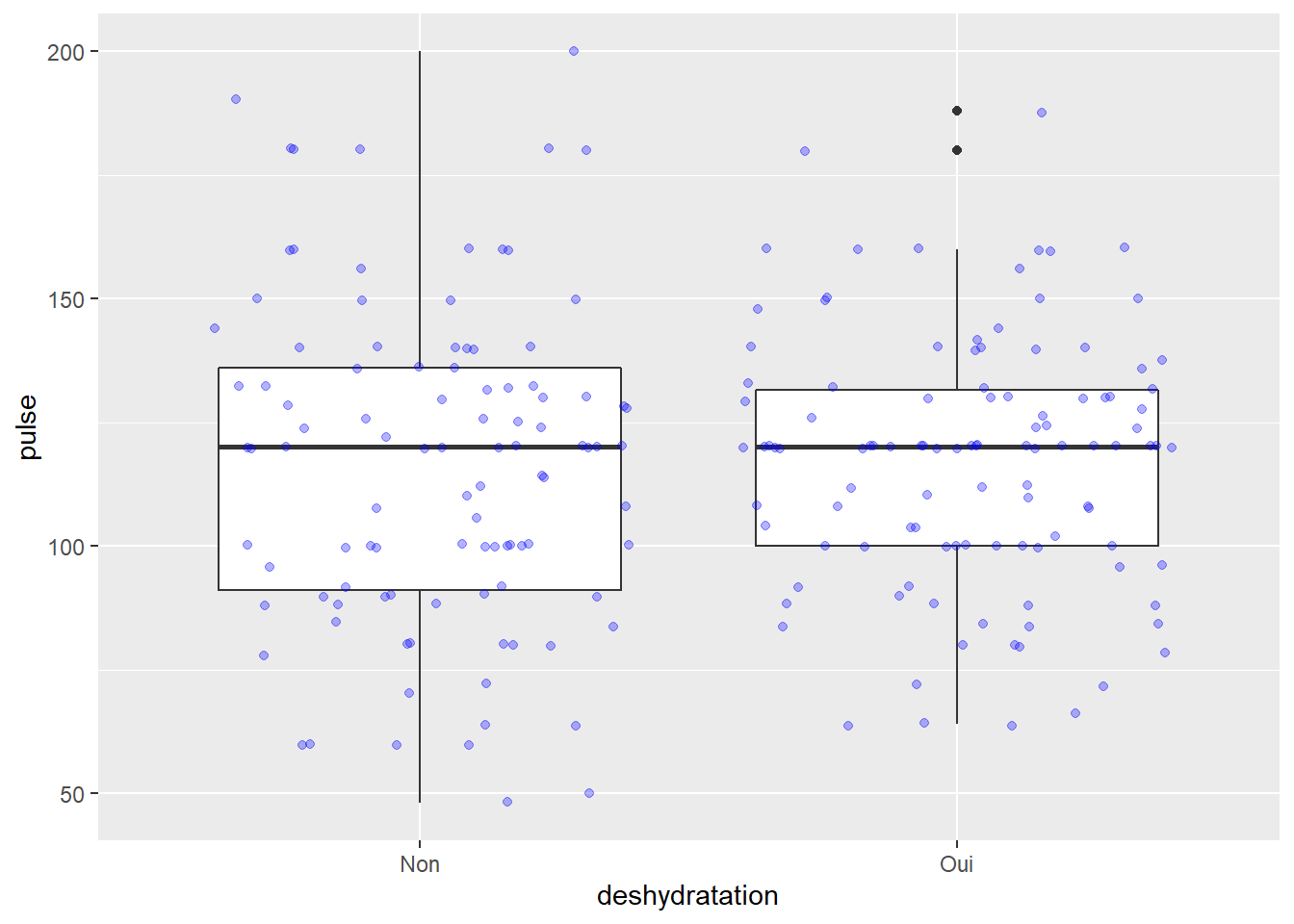
ggplot(veaux1, aes(x=deshydratation, y=pulse))+geom_boxplot() +
geom_jitter(color="blue", alpha=0.3, position=position_jitter(0.1))+ggtitle("j'ai spécifié une position de mon jittering plus regroupée que le défaut")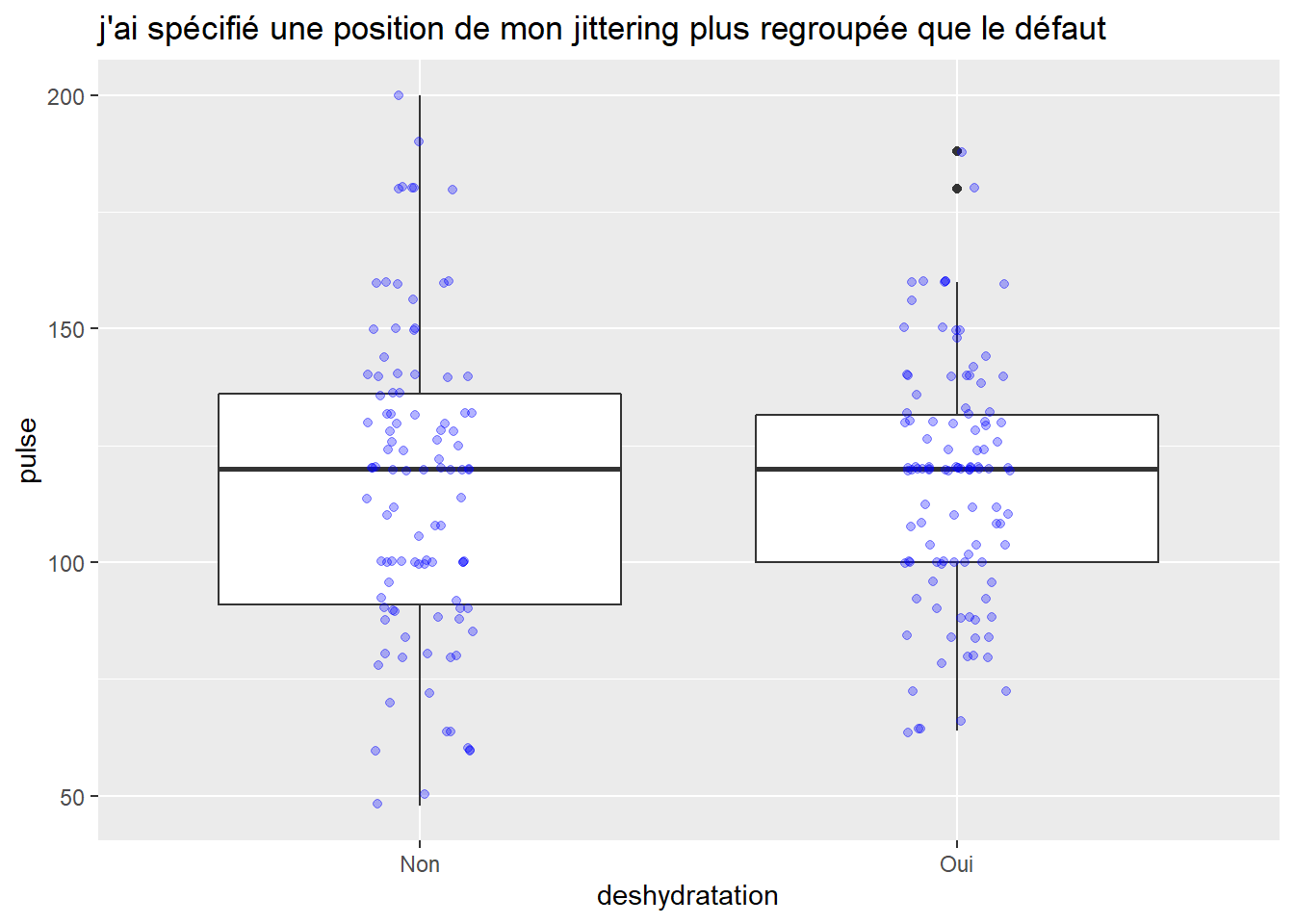
Notez que l’option jittering est intéressante mais qu’elle est générée aléatoirement donc si vous voulez toujours avoir le même visuel dans votre code vous devez spécifiez dans le geom une seed qui est un nombre que vous définissez (comme pour n’importe quelle commande aléatoire à des fins de répétabilité) qui va garantir que votre graph aura le même aspect à chaque fois que vous roulez votre code…
Je peux aussi essayer d’ordonner mes points plus spécifiquement afin d’améliorer le visuel…
ggplot(veaux1, aes(x=deshydratation, y=pulse))+geom_boxplot() +
# geom_jitter(color="blue", alpha=0.3) +
geom_dotplot(binaxis='y', stackdir='center', dotsize=1, color="blue", fill="yellow", alpha=0.3, binwidth=5)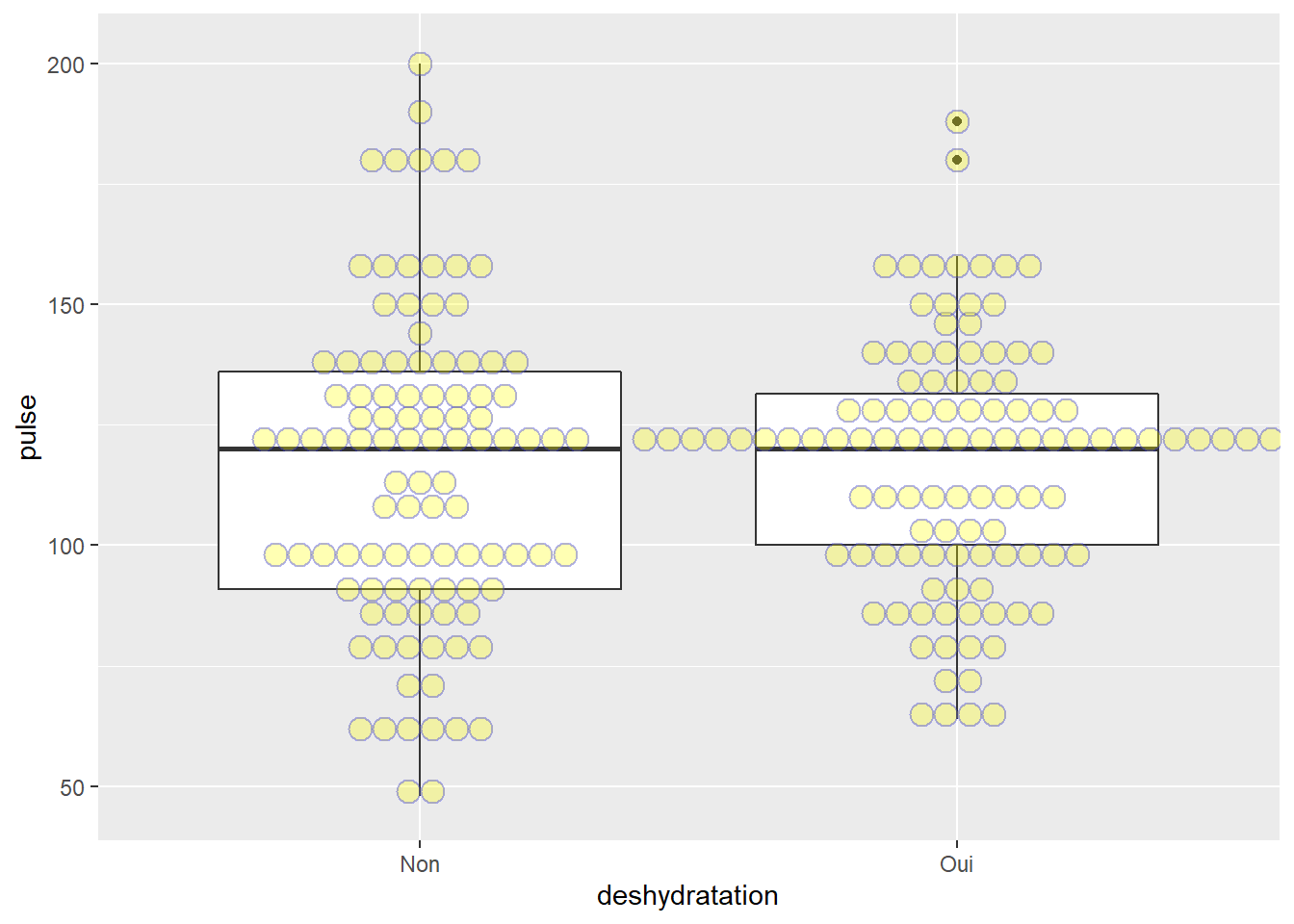
Prenons un peu de temps pour étudier les argument ici figurant dans le geom_dotplot.
1- binaxis il faut que j’indique que mon dot plot va représenter la variable continue (en y dans le cas de mon graphique boxplot…)
2- stackdir indique la localisation d’accolement des points (*ici les points sont centrés à partir des moustaches du boxx-plot)
3- binwidth qui indique la plage de regroupement de mes points sur l’axe des y (ici tous les points sur la même ligne représentent sont dans le même intervalle de 5 de la variable pulse (5bpm))
Notez que je peux bien sur adapter encore ce graphique…
Allez-y essayez par vous-même!!!
3.2.2 Alternative au box-plot le diagramme en violon (geom_violin)
Le box-plot a été très critiqué pour son manque de lisibilité concernant la distribution des données (voir par exemple ce blog qui défend les mérites du violin plot). Des distributions très différentes peuvent en effet avoir un aspect similaire. La figure en violon est, quant à elle, beaucoup plus informative notamment car elle permet de mieux voir la distribution. Sur SAS il existe une macro mais elle est assez longue et difficilement adaptable (en tout cas lorsque j’avais utilisé cela en 2018… depuis j’avoue je n’ai pas regardé si il y avait eu du nouveau…)
En résumé, pour moi le violin plot est comme un box plot mais BIEN MEILLEUR AU NIVEAU DE L’INFORMATION VISUELLE QUI EN EST TIRÉE.
ggplot(veaux1, aes(x=deshydratation, y=pulse)) +geom_violin(fill=c("lightgreen"), draw_quantiles = c(0.25, 0.5, 0.75)) #NB: l'option draw-quantile vous permet de mettre les quantiles que vous voulez dans ce diagramme. Ici j'ai mis médiane et quartile mais on peut mettre ce que l'on veut spécifiquement.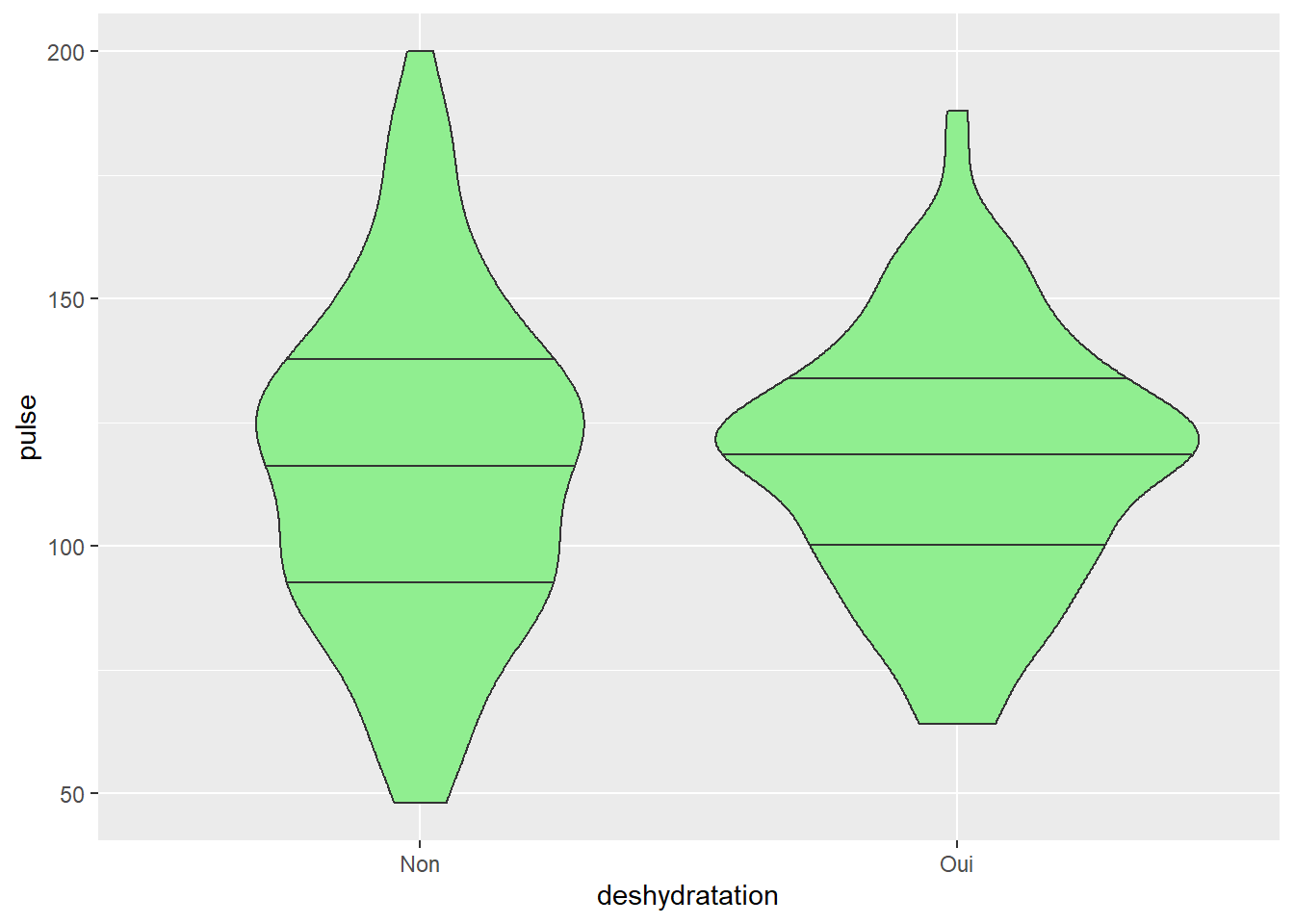
Je peux par la suite donner des couleurs spécifiques à mes groupes à condition de le spécifier initialement dans l’aes de mon statement ggplot
ggplot(veaux1, aes(x=deshydratation, y=pulse, fill=deshydratation)) +geom_violin(draw_quantiles = c(0.25, 0.5, 0.75)) + #nb l'option draw-quantile vous permet de mettre les quantiles que vous voulez dans ce diagramme
theme_classic() #pour mieux voir les contrastes...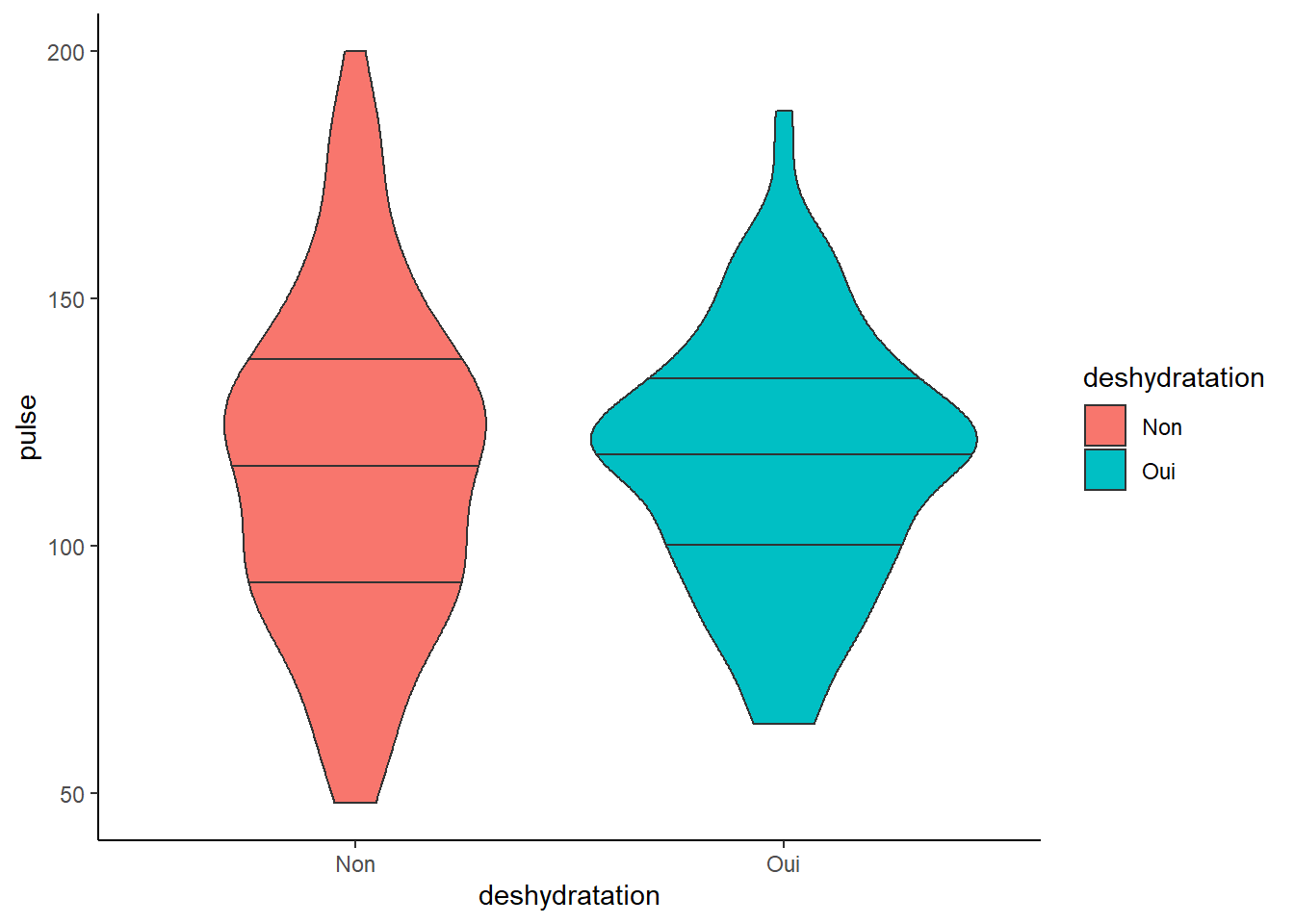
ggplot(veaux1, aes(x=deshydratation, y=pulse, fill=deshydratation)) +
geom_violin(draw_quantiles = c(0.25, 0.5, 0.75)) +
scale_fill_manual(values=c("#E69F00", "#56B4E9")) #argument pour spécifier des couleurs que je veux...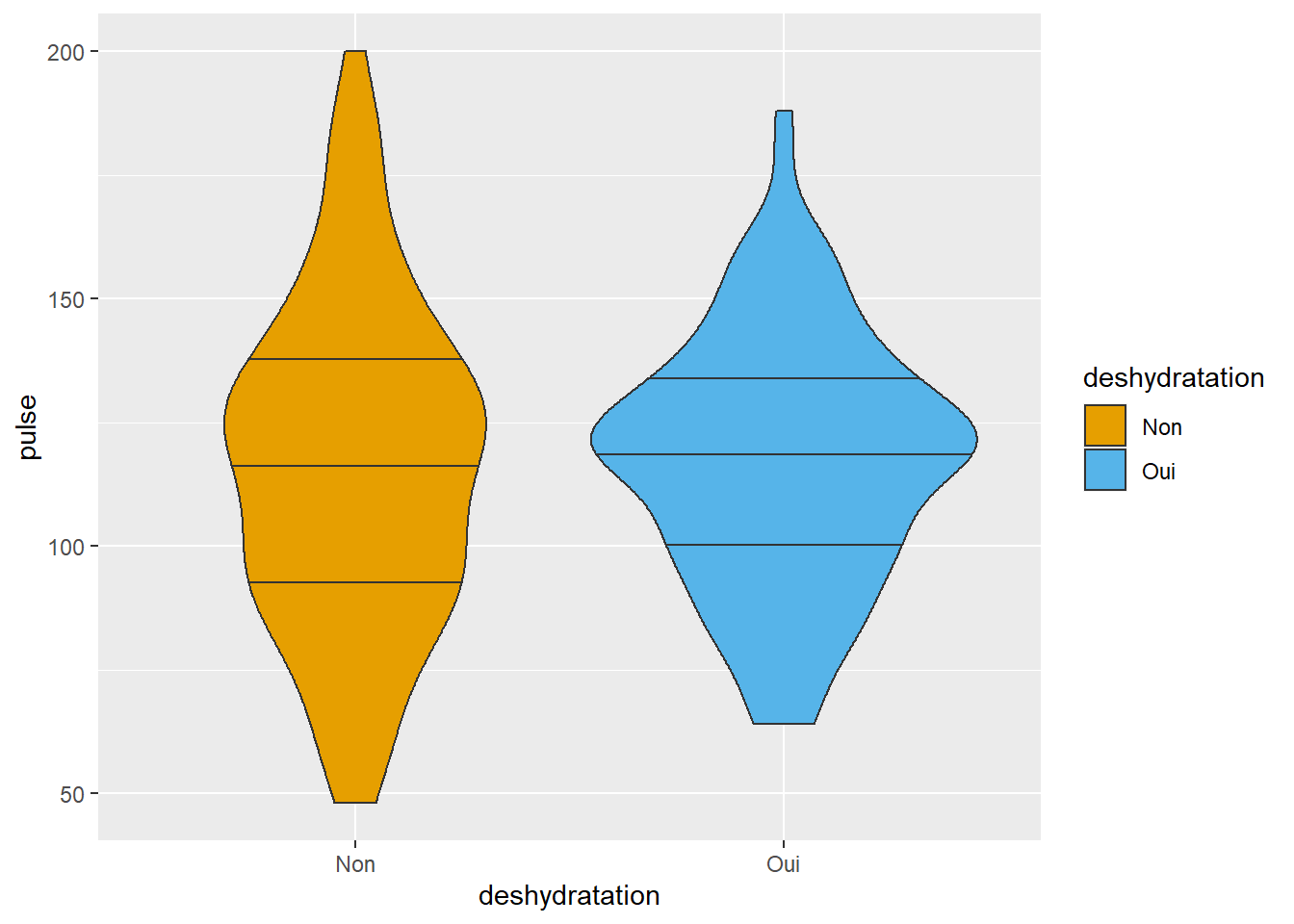
Notez que je pourrais me concentrer uniquement sur mon groupe d’intérêt les animaux déshydratés avec un l’utilisation d’un outil que vous ai présenté dans REMA-1 avec l’option filter
Je m’explique:
exemple <- veaux1 %>% filter(deshydratation=="Oui")
exemple %>% ggplot(aes(x=deshydratation, y=pulse)) + geom_violin(fill=c("lightgreen"), draw_quantiles = c(0.25, 0.5, 0.75)) 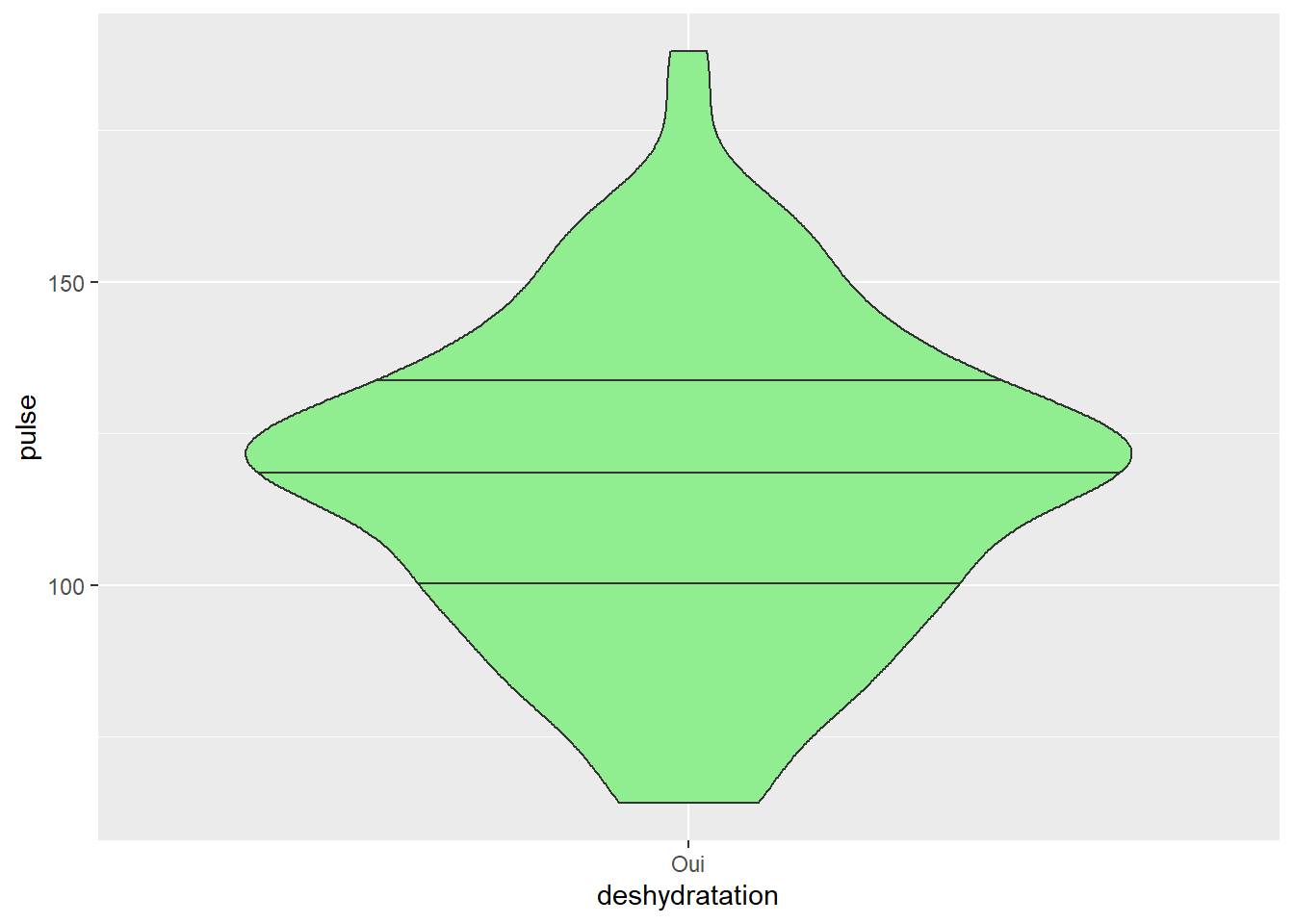
3.2.3 boxplot ou violin
Je ne prends pas de décisions pour vous… À vous de juger ce qui est le plus pertinent pour votre présentation ou publication.
Je vous mets juste un exemple ici qui vous permet de regarder les 2 graphs en parallèle grâce à la fonction ggarrange que nous verrons plus tard.
library(ggpubr) #ici c'est un paquet pour mettre 2graphs ensemble dans mon chunk et
a <- ggplot(veaux1, aes(x=deshydratation, y=pulse, fill=deshydratation)) +geom_boxplot()
b <- ggplot(veaux1, aes(x=deshydratation, y=pulse, fill=deshydratation)) +geom_violin(draw_quantiles = c(0.25, 0.5, 0.75))
ggarrange(a, b, common.legend=TRUE, nrow = 1) #ici juste pour les mettre en parallèle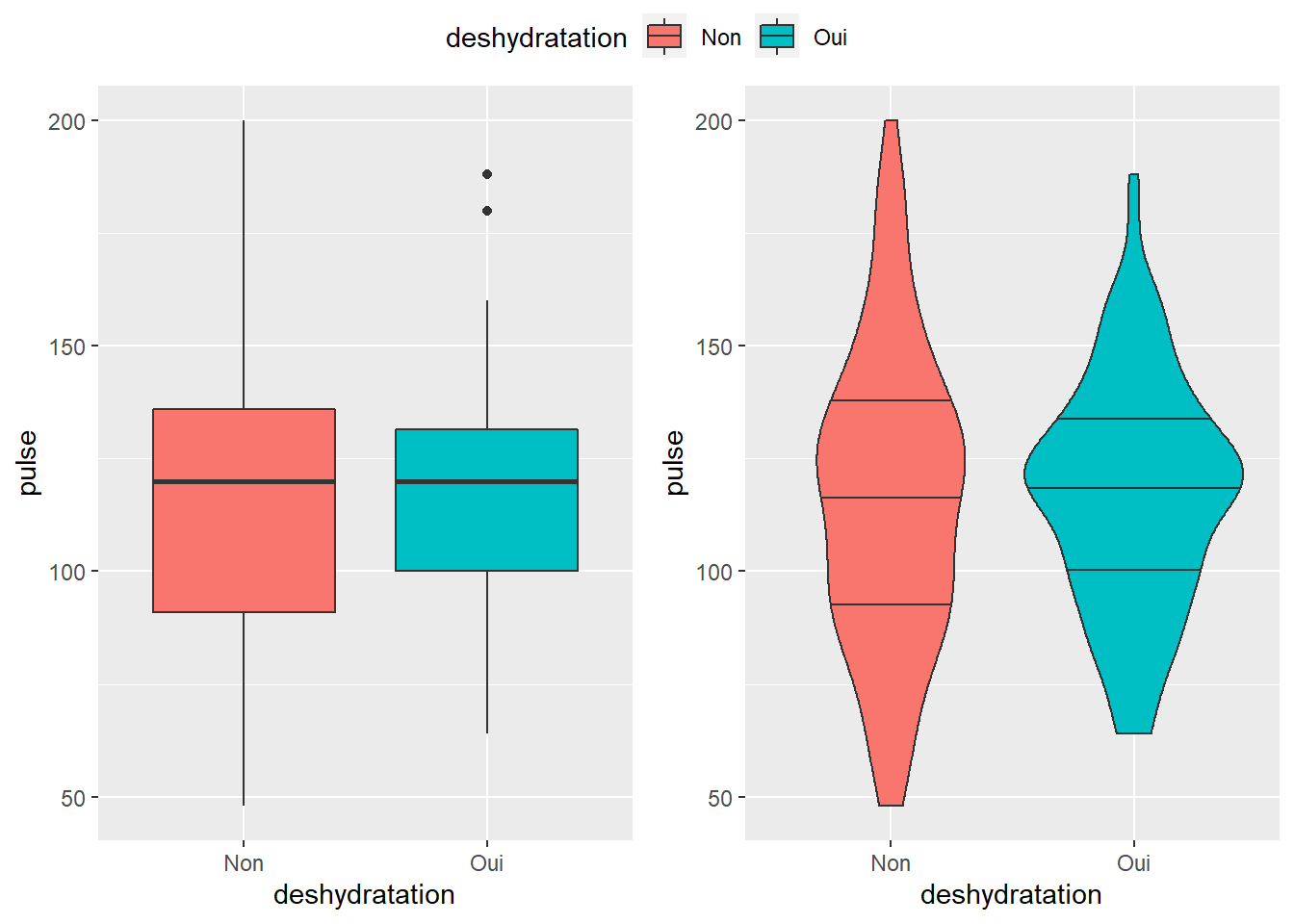
3.2.4 Inverser les x et les y par l’option coord_flip()
Parfois on voudrait tourner l’image pour un meilleur visuel…
Nous utiliserons alors tout simplement l’option coord_flip() qui permet de rapidement changer l’orientation des axes (le x devient le y et réciproquement)
C’est super simple, il suffit d’ajouter l’option à la fin de votre code initial
Avouez que là vous commencez à trouver que c’est trop bien!!!
c <- ggplot(veaux1, aes(x=deshydratation, y=pulse, fill=deshydratation)) +geom_boxplot() + coord_flip()
c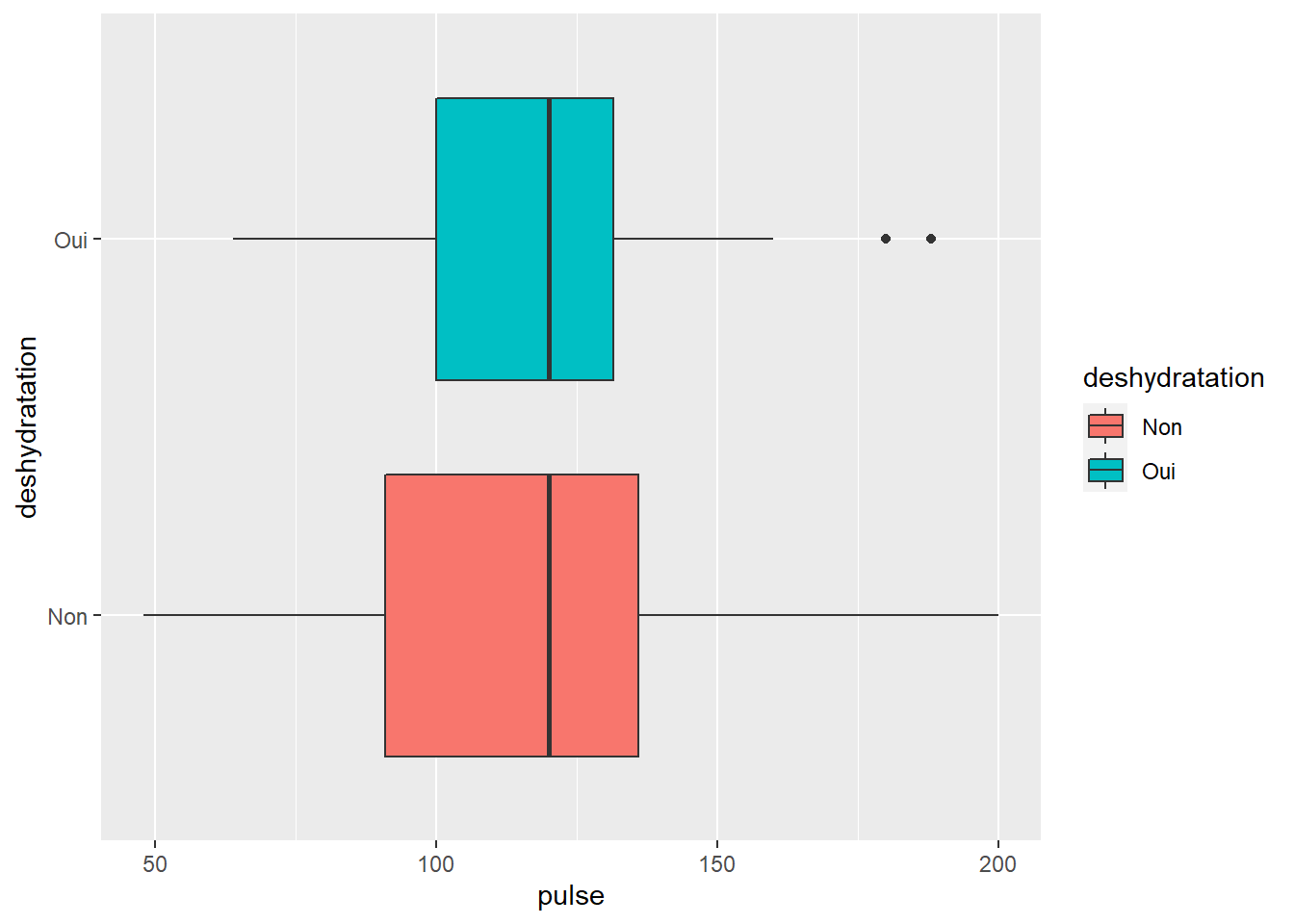
d <- ggplot(veaux1, aes(x=deshydratation, y=pulse, fill=deshydratation)) +geom_violin() + coord_flip()
d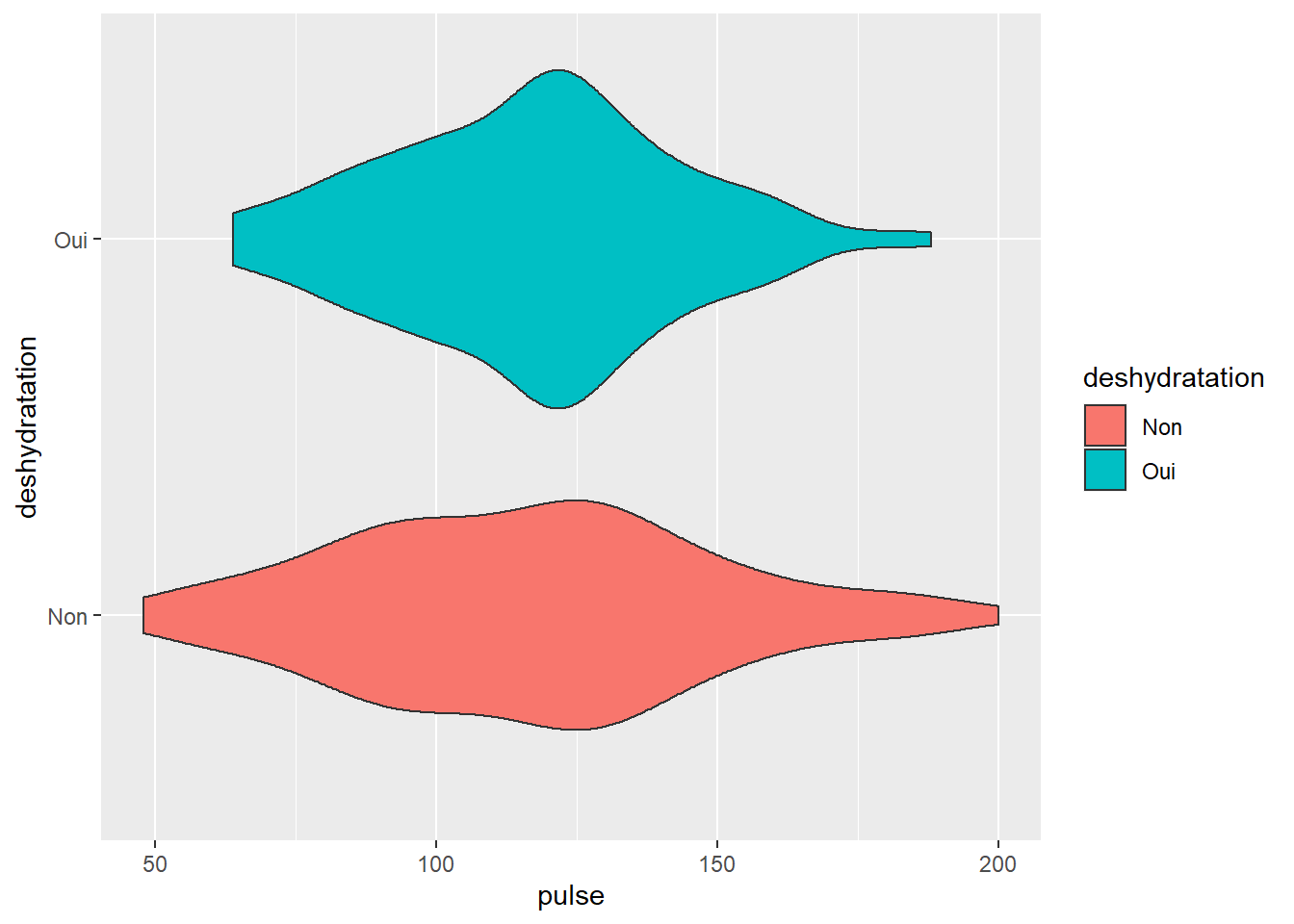
ggarrange(c,d, ncol = 1, common.legend=TRUE) # je représente les 2 graphs en spécifiant que je veux le tout en une seule colonne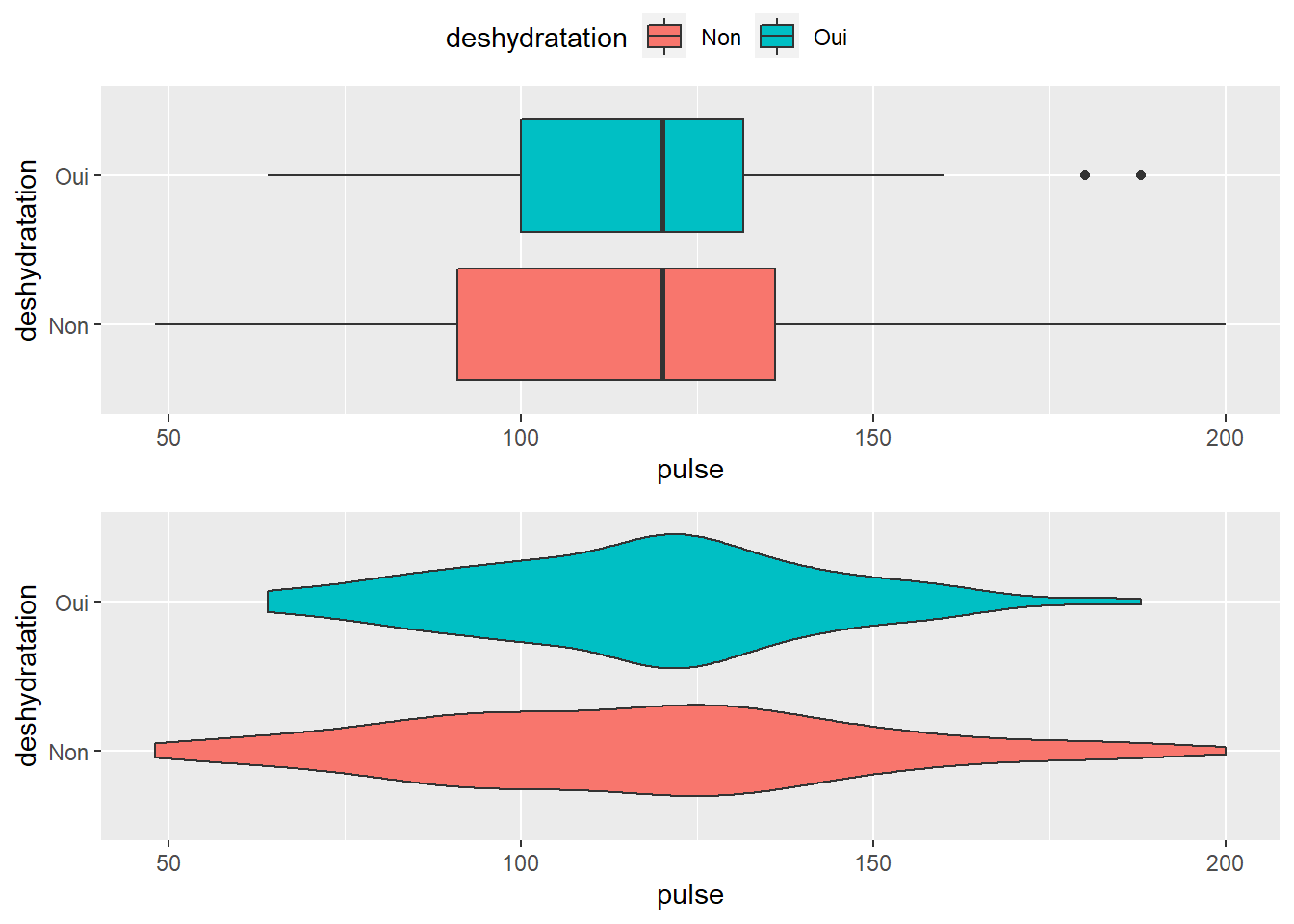
4. Faire apparaitre des panneaux multiples pour mieux visualiser: “facettons!!!”
Vous vous souvenez que nous avions utilisé le code précédent pour voir l’association de l’age sur la relation entre pulse et dehy. Nous avons par exemple utilisé le code suivant:
ggplot(data=veaux, mapping=aes(x=dehy, y=pulse,color=age))+geom_point() 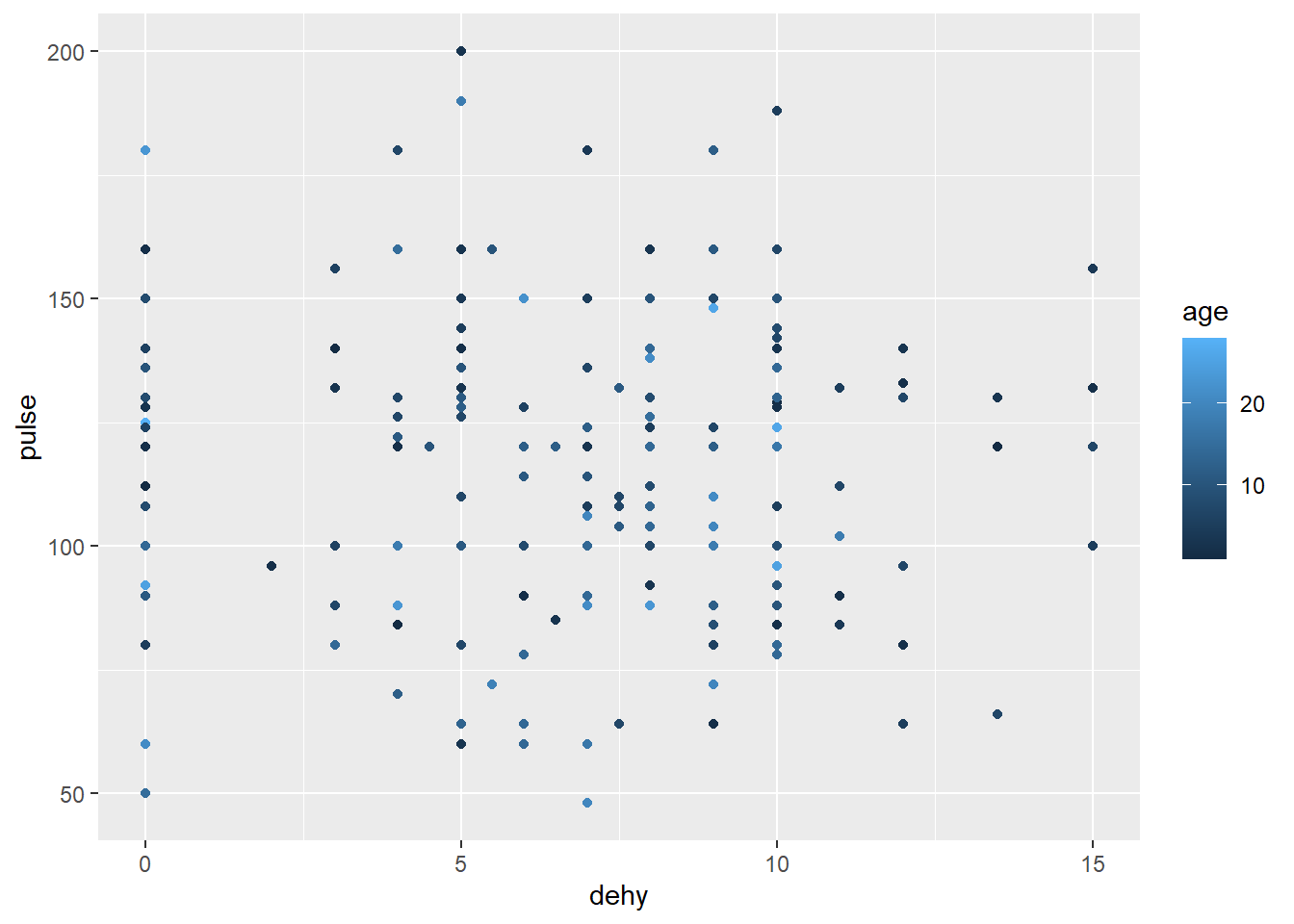
#ou encore
ggplot(data=veaux, mapping=aes(x=dehy, y=pulse, size=age))+geom_point() 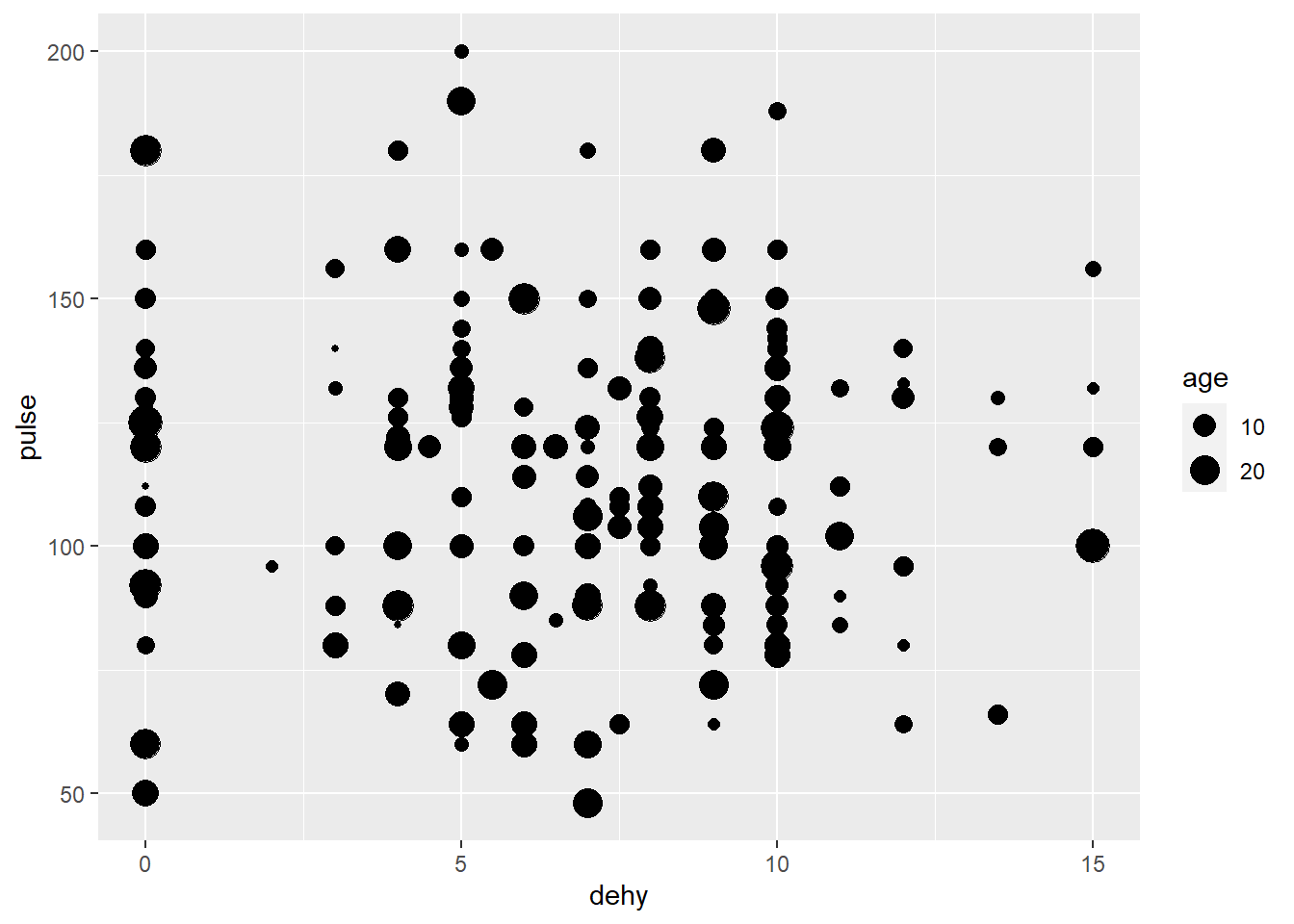
On voit ici que dans les 2 cas, le message que l’on peut tirer de cette image est limité (il est en effet difficile de s’assurer qu’il y a ou pas une relation entre l’age et mes 2 variables).
Dans un premier temps, on pourrait voir si en regroupant les données par l’age on gagnerait en lisibilité. Pour se faire je vais transformer age en données de type facteur et regarder l’impact en terme de données. Pour des raisons de clarté du graph et de la base de données on va essayer de résumer l’information par semaine d’âge (en catégorisant…)
#avant toute chose je regarde la distribution de mes données age
ggplot(veaux, aes(x=age)) + geom_histogram(bins=40)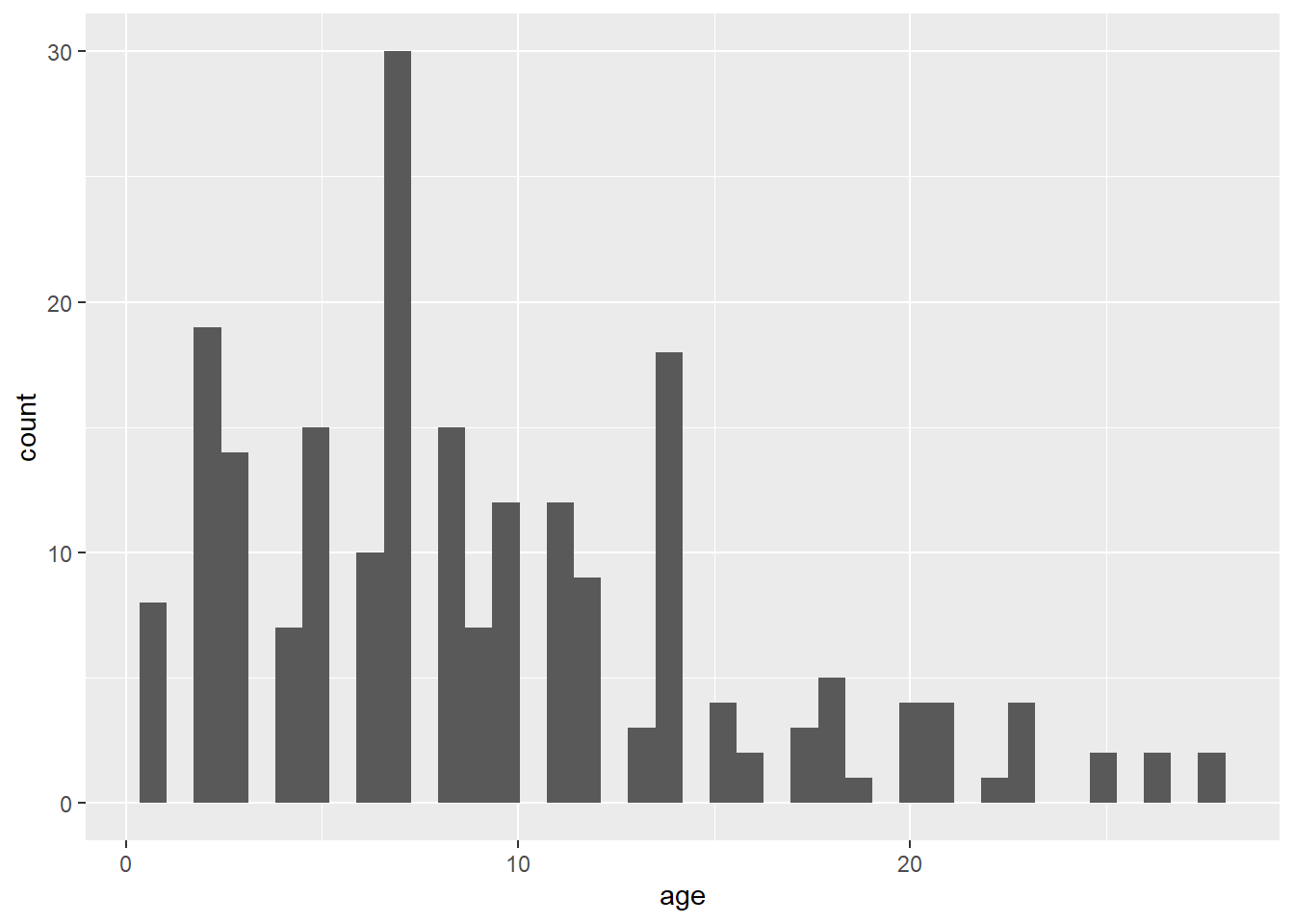
# sans faire de gros calculs (et à des fins d'exemple) on peut voir que diviser en moins de 7j, 7 à 14 et plus de 14j pourrait donner du sens (cela fait juste 3 groupes donc c'est ce que je voulais (>2 groupes pour la démonstration des facettes))
#encore une fois c'est pour des fins de démonstration, n'y voyez aucune forme de choix rationnel...
#dans un premier temps je vais créer la variable age_f qui sépare mes données en fonction de ces principes
veaux$age_f=cut(veaux$age,breaks=c(0,8,15,100),
include.lowest=TRUE,#inclus dans le groupe la limite inférieure de la borne par exemple le 8 est inclus dans le groupe 8-14j
labels=c("7j ou moins","8 à 14j","15j et plus"), na.rm=TRUE)
table(veaux$age_f)##
## 7j ou moins 8 à 14j 15j et plus
## 118 65 30ggplot(data=veaux, mapping=aes(x=dehy, y=pulse, color=age_f, fill=age_f)) +
geom_point() +
geom_smooth(method="lm")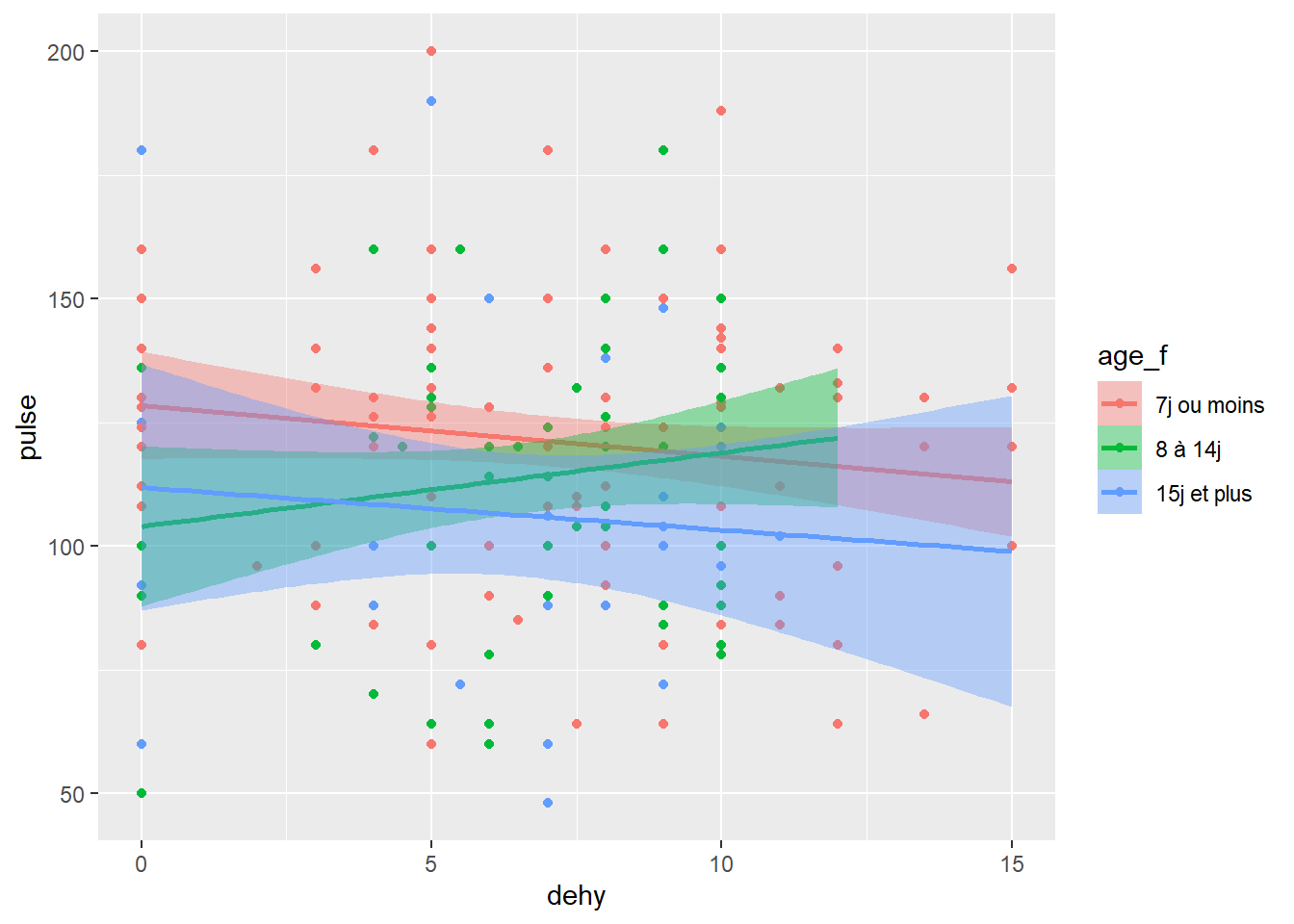
#ici on voit un peu mieux les 3 variables d'intéret mais l'incertitude autour de ma ligne limite la visibilité...
ggplot(data=veaux, mapping=aes(x=dehy, y=pulse, color=age_f, fill=age_f)) +
geom_point() +
geom_smooth(method="lm", se=FALSE) #ici j'élimine l'incertitude pour me concentrer sur la ligne de tendance principale...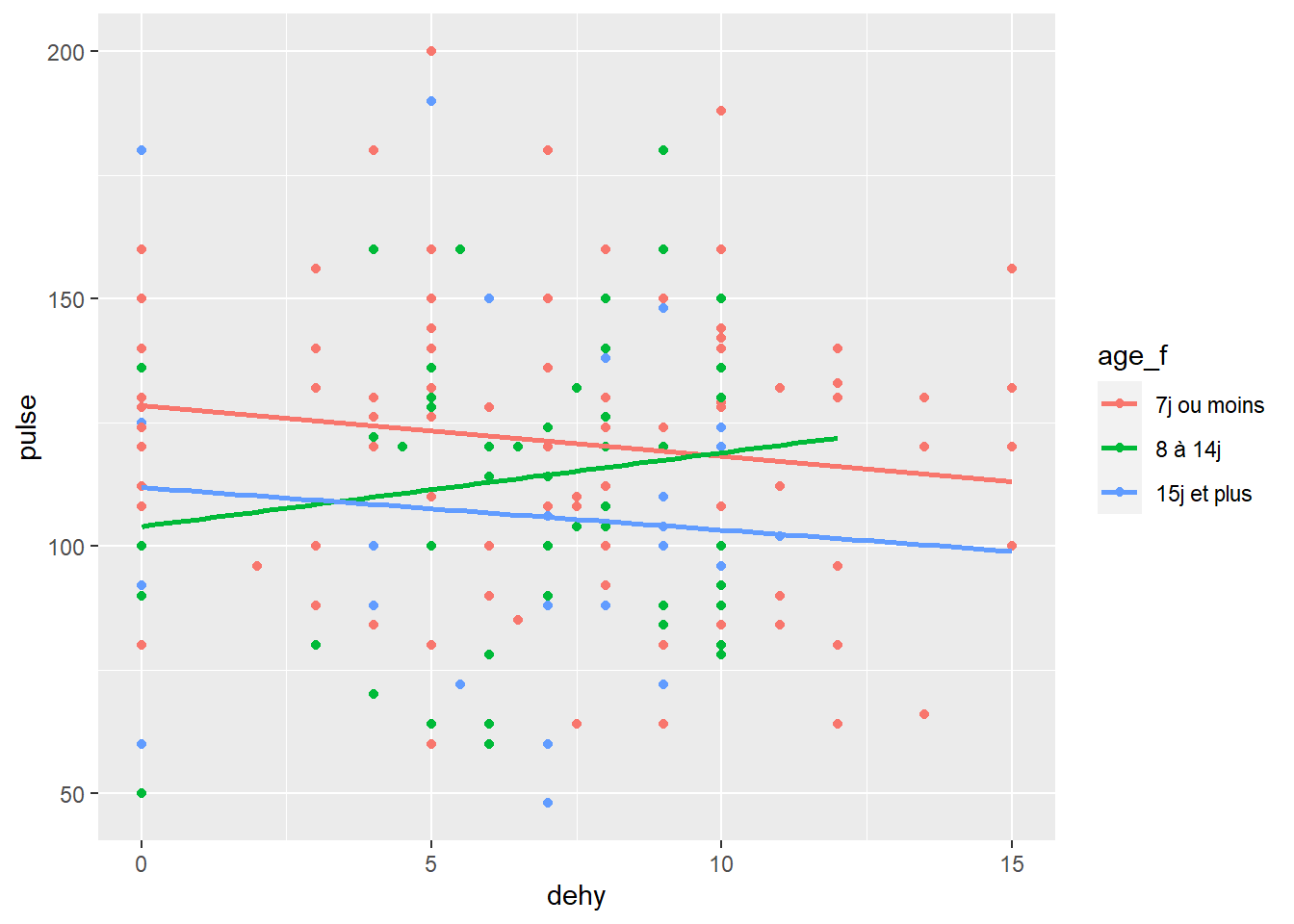
On pourrait encore faire mieux car ce n’est pas forcément évident de bien voir la distinction des points selon l’âge (peut être aussi du à mon choix de couleur de points par défaut)….
4.1 Argument facet_grid
Ici j’introduis une nouvelle fonction qui est la fonction facet_ . Cette fonction va nous permettre de subdiviser notre/nos geom_ sous la forme de panneaux qui nous permettent d’éviter la superposition. c’est surtout utile quand on a des grandes BD où la superposition est un facteur limitant à la perception de notre oeil/cerveau…
Il y a différentes notions dans le facetting avec facet_grid et facet_wrap. Je vous renvoie vers le site de R Cookbook.
l’argument facet_grid vous donne la possibilité spécifique de diviser vos données selon plusieurs variable et la sortie du graph se fera en fonction du nombre de catégories (ci-dessous les 4 types de catégories sont sur la même ligne).
ggplot(data=veaux, mapping=aes(x=dehy, y=pulse, color=age_f, fill=age_f)) +
geom_point() +
geom_smooth(method=lm) +
facet_grid(~age_f)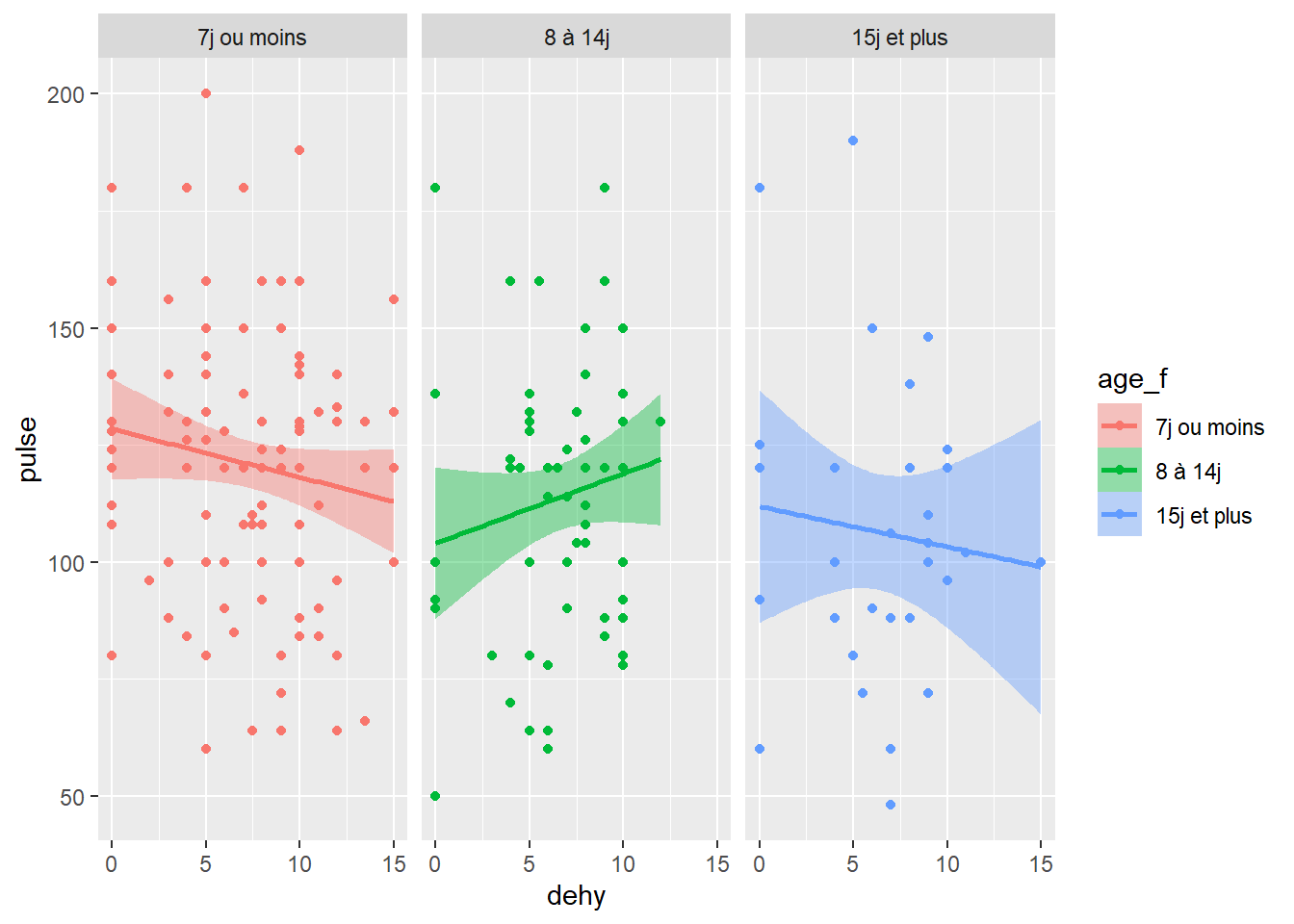
Un des intérêts spécifiques de facet_grid est la possibilité de spécifier une visualisation selon plusieurs variables.
Exemple: admettons que je veuille en plus ajouter dans ma visualisation de l’effet de l’âge, l’impact du sexe de mes veaux. Implicitement l’argument facet_grid(var1~var2) me donnera mon graph avec variable 1 en ligne et variable 2 en colonne.
Rappelez vous que R fonctionne en (ligne, colonne) dans tous les arguments (cf REMA-1)
ggplot(data=veaux, mapping=aes(x=dehy, y=pulse, color=age_f, fill=age_f)) +
geom_point() +
geom_smooth(method=lm) +
facet_grid(sex~age_f) #rappelez vous 0=mâle et 1 =femelle....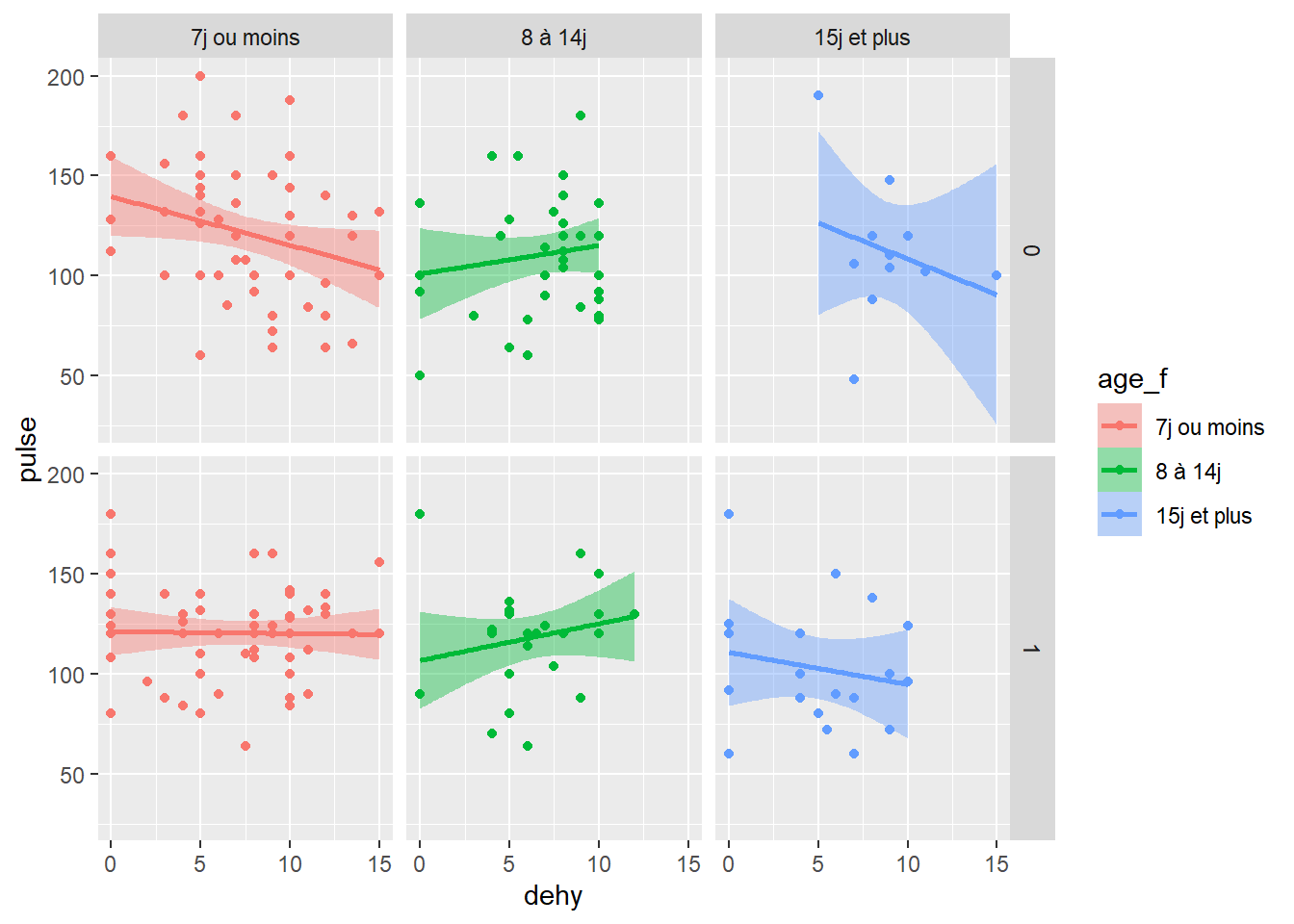
Juste visuellement ici, je peux voir que la relation (si je me fie aux droites) change selon la strate d’âge et qu’il y a aussi un impact du sexe pour la catégorie 0-7j selon que ce sont des mâles (pente descendante) ou l’absence de relation (pente nulle pour sexe=1, 7j ou moins)…
4.2 Argument facet_wrap
facet_wrap me permet de spécifier le nombre de lignes (nrow=) ou de colonnes (ncol=) que je veux…
Ci-dessous par exemple, je spécifie que je ne veux qu’une seule colonne pour superposer mes facettes (ncol=1)
ggplot(data=veaux, mapping=aes(x=dehy, y=pulse, color=age_f, fill=age_f)) +
geom_point() +
geom_smooth(method=lm) +
facet_wrap(~age_f, ncol=1)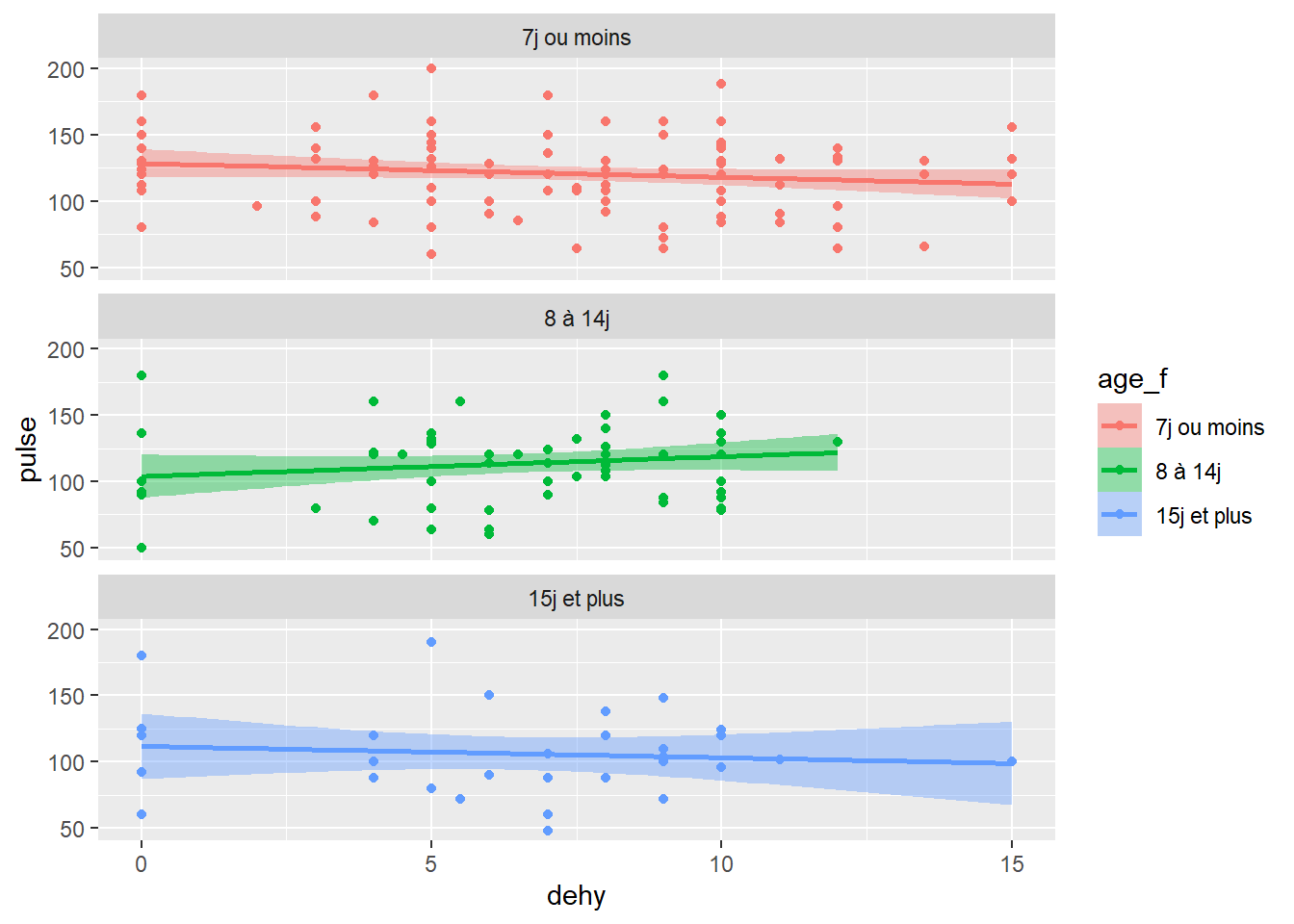
5. Modifier l’apparence de l’arrière plan, ajouter des lignes, des formes, du texte et la mise en page…
5.1 Modifier l’apparence avec theme_
Jusqu’à présent, vous avez vu le thème par défaut de l’arrière plan de ggplot.
Vous vous dites peut-être que le fond du graphique pourrait être mieux. On peut bien sur modifier cela facilement avec l’option theme_.
g+geom_point() + theme_bw()
g+geom_point() + theme_classic()
g+geom_point() + theme_linedraw()
Ce ne sont que des exemples à titre indicatif (voir ggtheme pour les choix possibles). Personnellement theme_bw() et theme_classic() sont mes préférés.
Si vous ne trouvez pas votre bonheur vous pouvez aussi ajouter des thèmes issus du paquet ggthemes. Avis aux intéressés…
library(ggthemes)
g+geom_point() + theme_void() #aucune information
g+geom_point() + theme_wsj() #theme wall street journal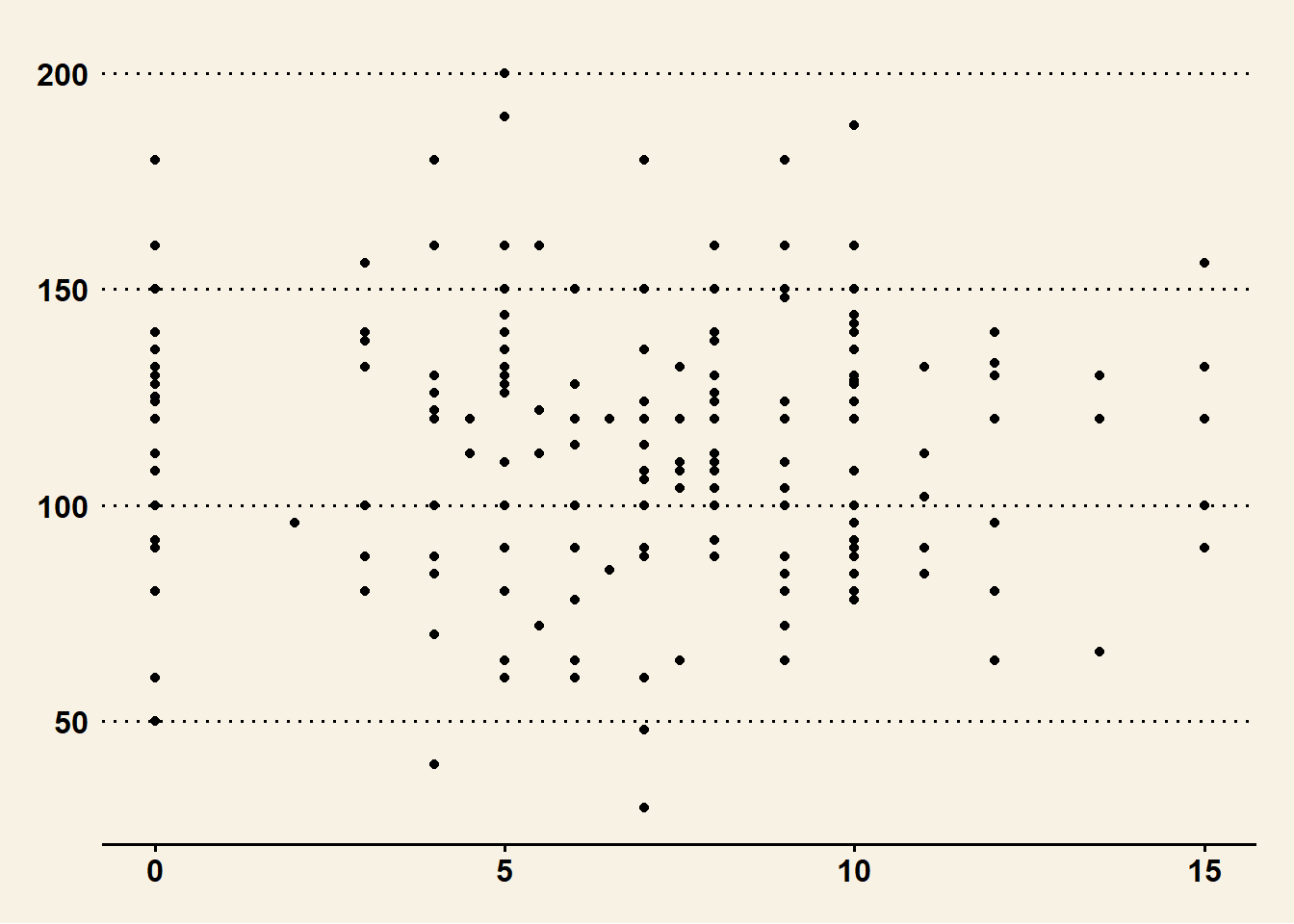
g+geom_point() + theme_stata() #comme le type de graph de sortie par le logiciel Stata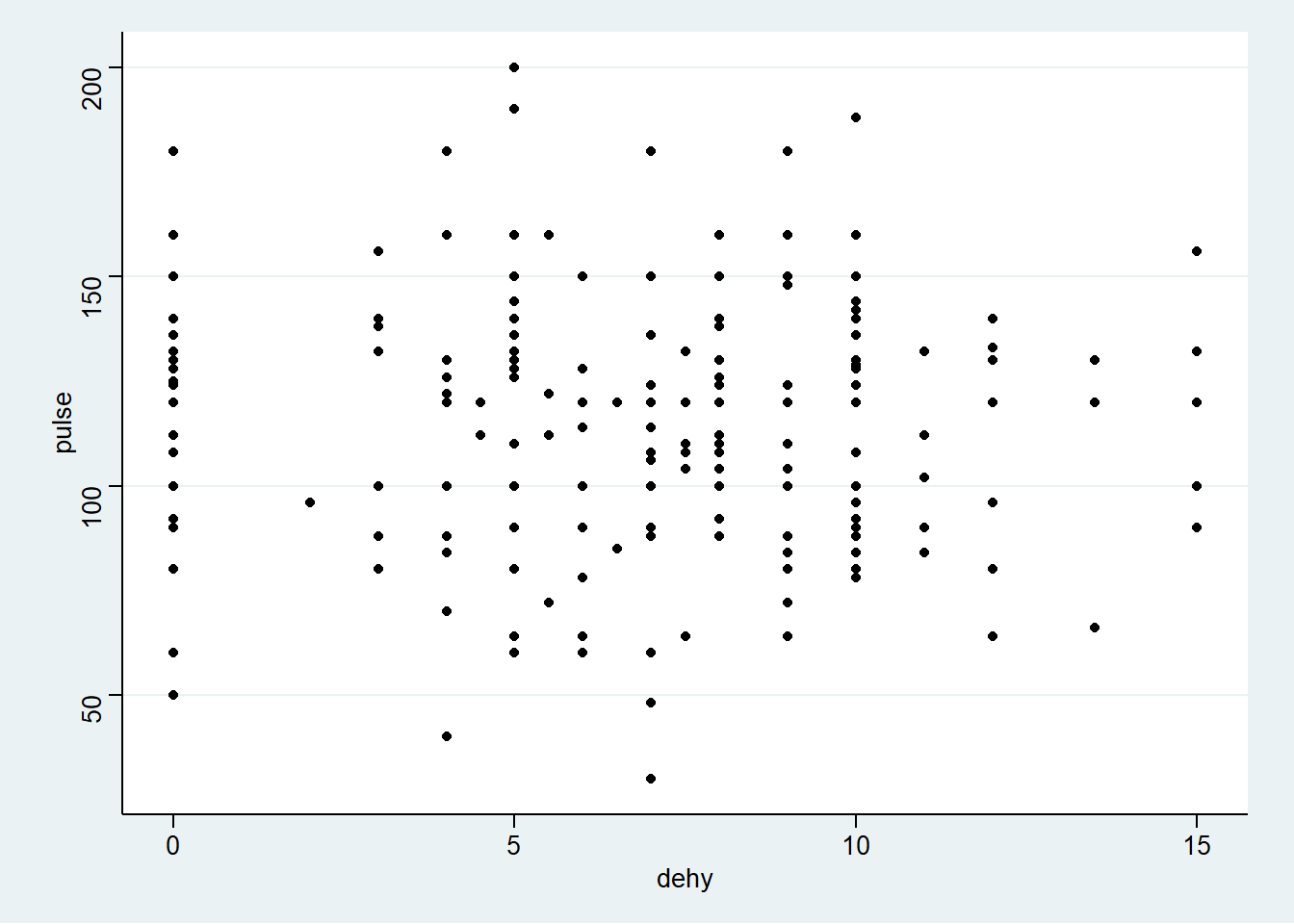
# bref j'en passe...Donc vous voyez, nous ne sommes pas limités.
5.2 Renommer les axes et mettre ajouter un titre au graphique
Là encore nous pouvons adapter le graphique… en modifiant les intitulés des axes avec labs().
Nous pouvons aussi ajouter un titre au graphique avec l’option ggtitle().
g+geom_point() + labs(x="Déshydratation (%)", y="Fréquence cardiaque (bpm)") +ggtitle("Nom sympathique")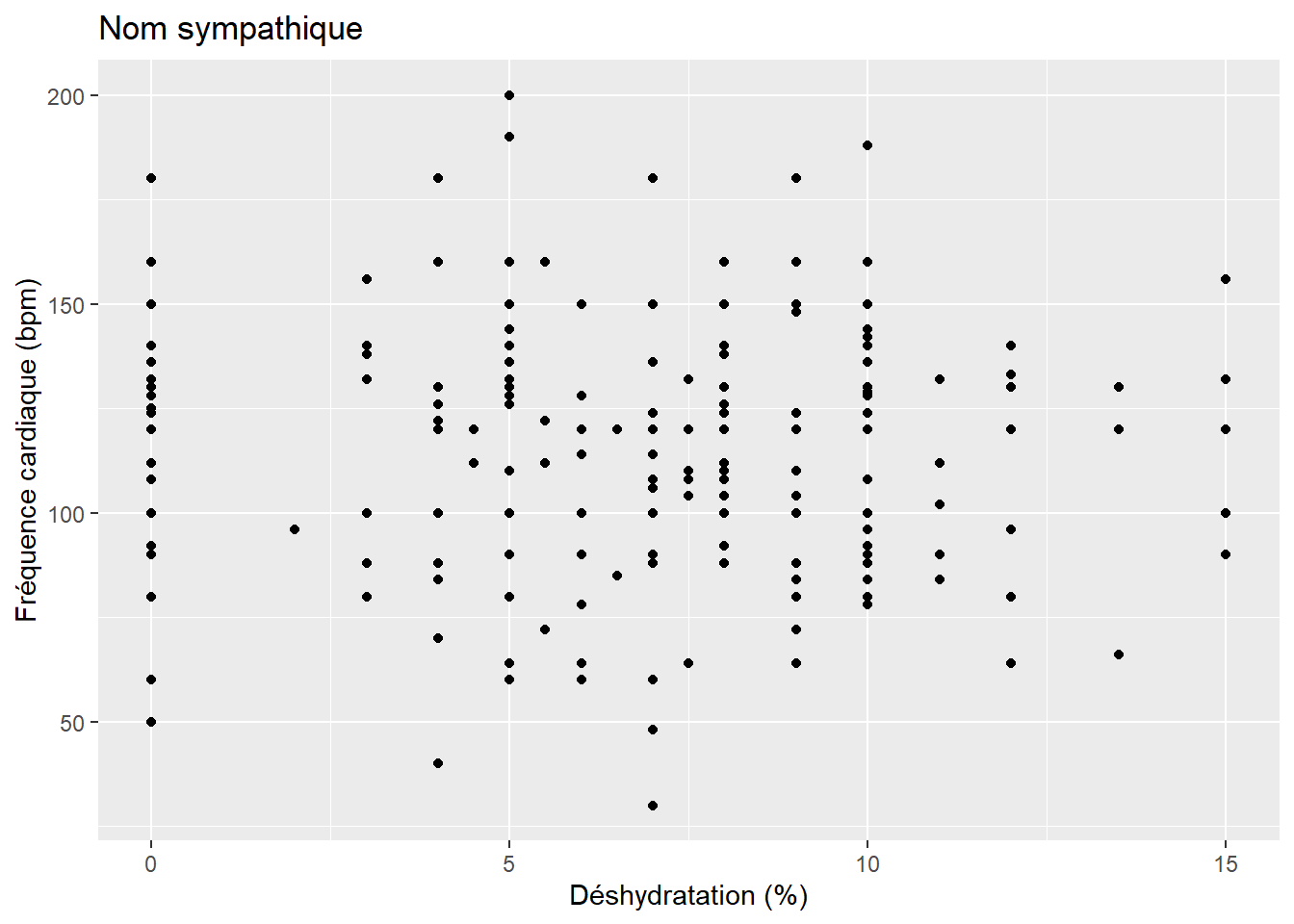
5.3 Spécifier l’étendue des axes
On peut aussi spécifier les marges de visualisation des axes (limites).
g+geom_point(color="red") +theme_bw() + labs(x="Déshydratation (%)", y="Fréquence cardiaque (bpm)") +ggtitle("Nom de figure sympathique") + xlim(0,20) +ylim(0,200)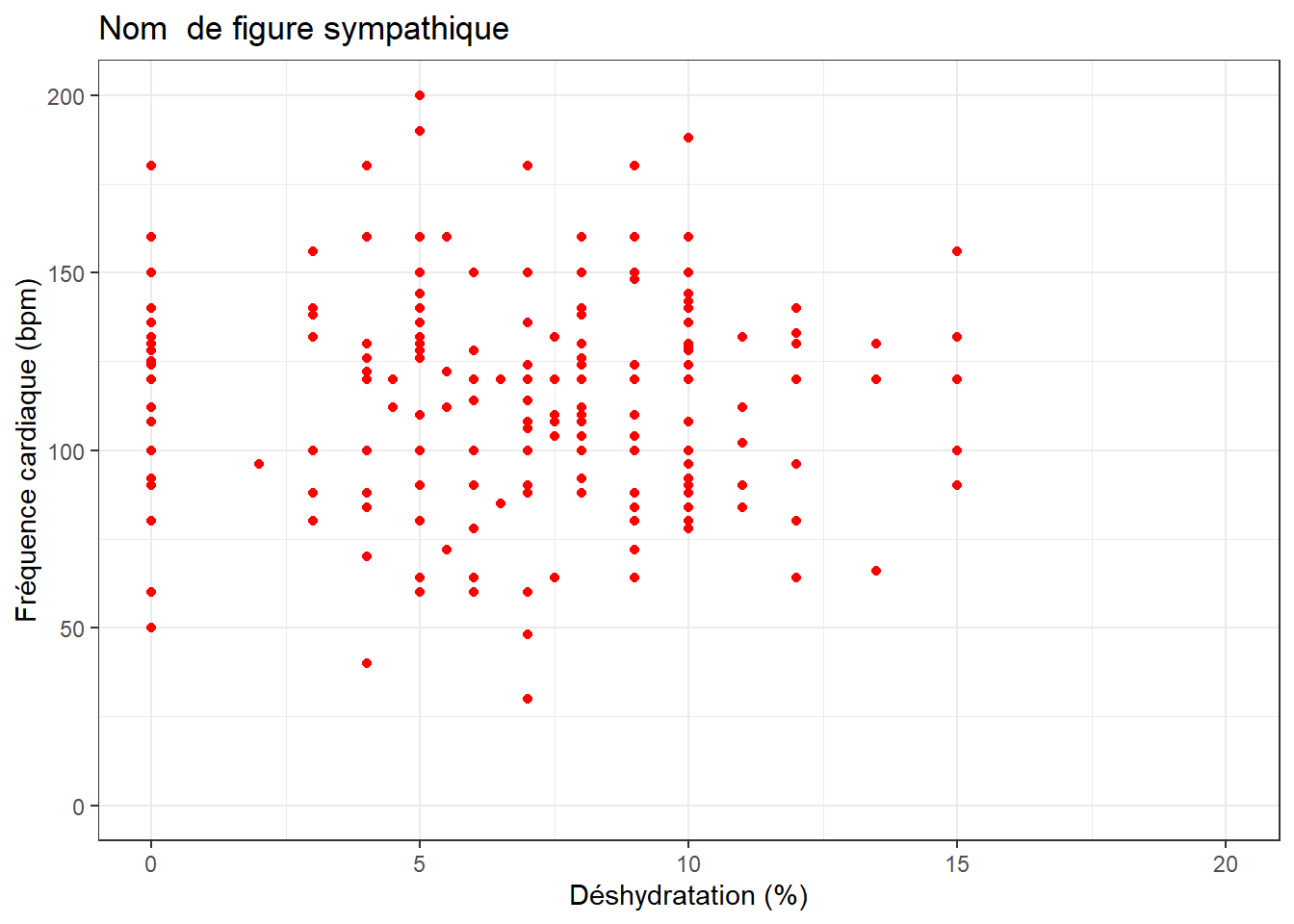
Notez ici que j’ai changé les limites des axes simplement en ajoutant les fonctions xlim et ylim. Donc c’est TRÈS facile… et ce n’est qu’un début…
Je peux aussi modifier l’orientation et la police de la notation des axes avec l’option theme()
g+geom_point(color="red") +theme_bw() + labs(x="Déshydratation (%)", y="Fréquence cardiaque (bpm)") +
ggtitle("Nom de figure sympathique") +
xlim(0,20) +
ylim(0,200) +
theme(axis.text.x = element_text(face="bold", color="darkgreen",
size=14, angle=-45)) #en gras, en vert et rotation de -45 degrés et une taille de 14...
Il y a tout un tas d’autres choses que vous pouvez faire sur les axes donc je vous y renvoie vers le site stdha …
Vous pouvez aussi mettre la gradation en log avec scale_x_log() ou d’autres arguments du type scale_x_().
5.4 Indications sur le graphique
Prenons un cas concrêt. vous avez un graphique où vous voulez indiquer une région qui vous parait intéressante. Traditionnellement (en tout cas avant dans mon anciennne vie), je prenais la figure sur PPT ou sur adobe et j’ajoutais manuellement pour enregistrer ensuite la modification avec la perte d’information inhérente à ce processus.
Heureusement, plus besoin de faire cela maintenant. On peut l’indiquer directement sur notre graph sans perdre de résolution graphique…
On utilise la fonction annotate() qui va nous permettre de mettre ce que l’on veut. Je vous réfère à la page spécifique sur ce sujet. Voici un exemple ci-dessous:
g+geom_point(color="red") +theme_bw() + labs(x="Déshydratation (%)", y="Fréquence cardiaque (bpm)") +
ggtitle("Mettre en évidence une zone d'intérêt") +
annotate (geom="rect", xmin=9, xmax=15.1, ymin=50, ymax=100, fill="purple", alpha=0.2) +
#ici j'ajoute un rectangle dont je spécifie les limites sur mes 2 axes
annotate("text", x = 12, y = 50, label = "FC basse malgré la déshydratation", angle=10 ,color="purple") #les arguments x et y indiquent le centre du texte. J'ai indiqué la rotation de 10 degrés juste pour vous montrer le tout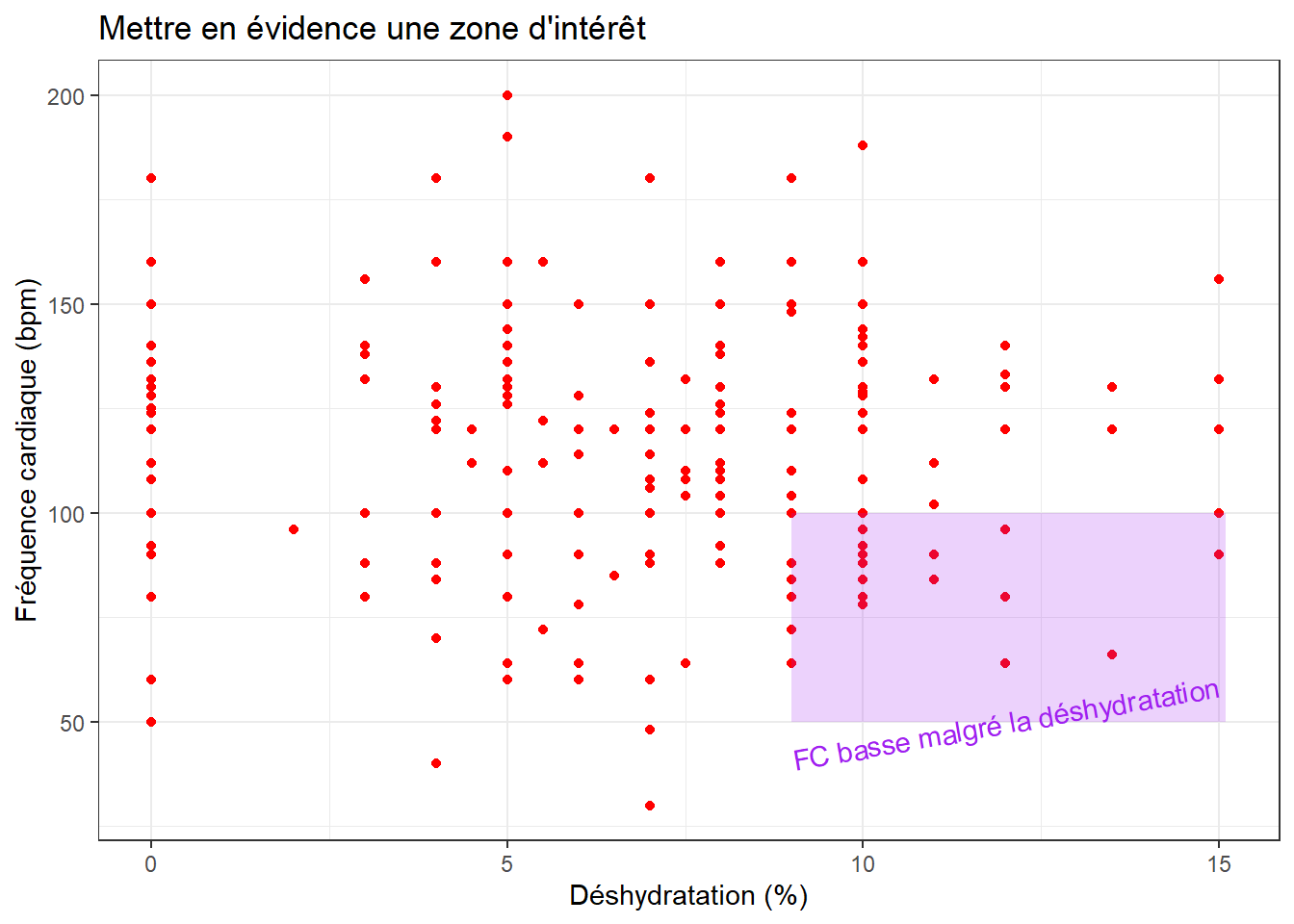
Bref, vous voyez que c’est quelque chose de très pratique qui peut être facilement modulée…
5.5 Indication spécifiques issues de la base de données.
5.5.1 Voir les infos des données
g+geom_point(color="red")+
theme_classic() +
geom_text(mapping=aes(label=sex), hjust=2, vjust=1) #ici j'ai demandé à voir pour chaque point la variable sex.
#j'ai utilisé vjust et hjust pour ajouter une justification verticale et horizontale.5.5.2 Voir les infos relatives à certaines données vs les autres données
Bien sûr vous vous doutez que ce n’est pas pertinent de regarder cela dans notre BD avec tant de points. Cependant, imaginons que vous avez la volonté de voir un animal ou une catégorie d’animaux de votre base de données de façon illustrée directement sur votre graphique.
Ex: Je veux voir les veaux 9805, 4869 et 2926 (les veaux issus du code tail(veaux, n=3) donc les 3 derniers veaux de ma BD, j’ai pris quelque chose pour des fins d’illustration). J’ai différentes options: la première est tout simplement de demander d’indiquer spécifiquement les points que je veux colorer différemment.
ggplot(data=veaux, mapping=aes(x=dehy, y=pulse, label=case))+ #ici je dois spécifier la variable dont je vais me servir pour afficher certaines donnés ou pas
geom_point(color = ifelse(veaux$case=="9805"|veaux$case=="4869"|veaux$case=="2926", "green", "red")) + #ici je cherche simplement les veaux dans ma BD et j'indique la couleur de ces cas spécifiques.
theme_classic()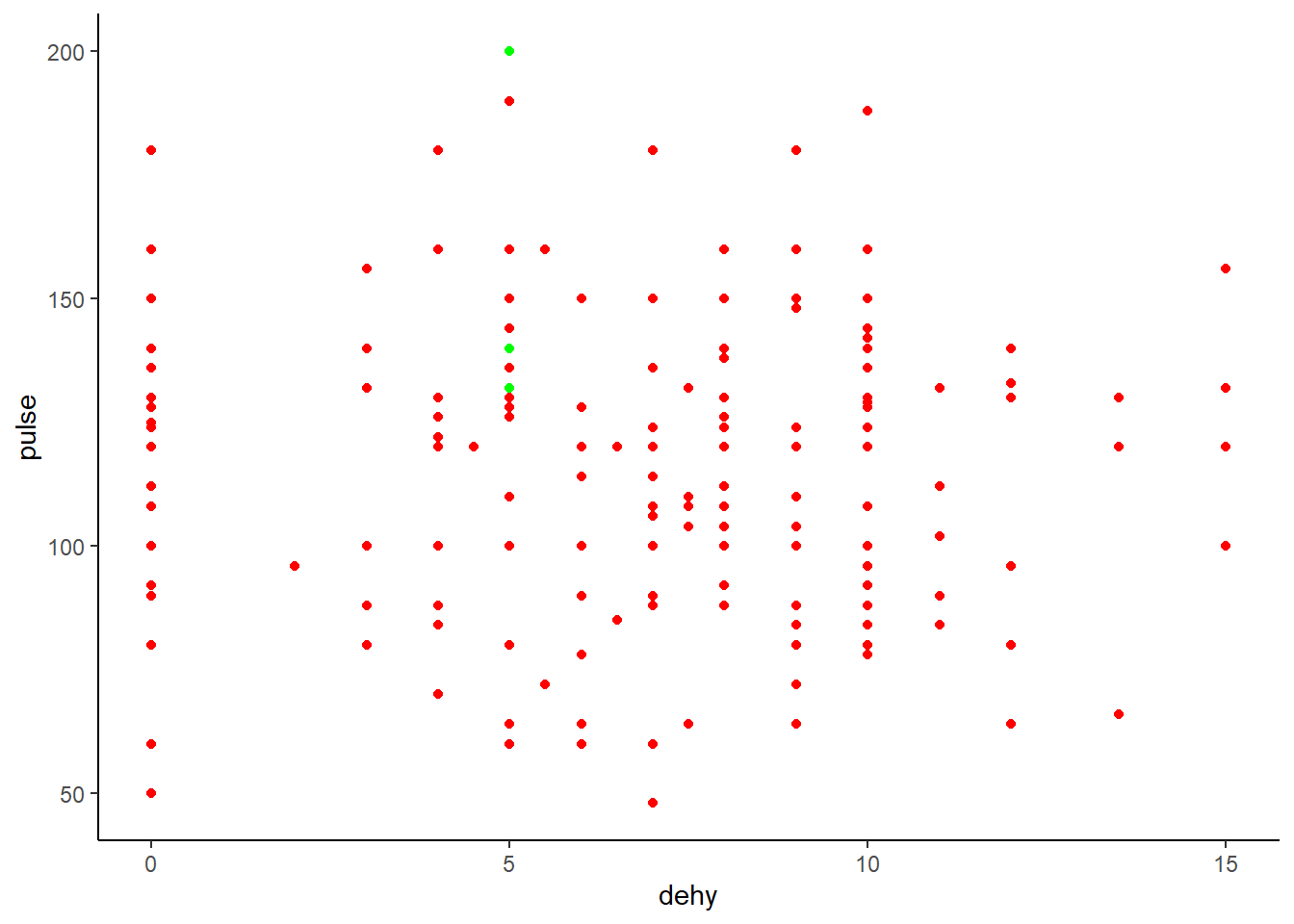
Pour la seconde je ne peux pas le faire avec uniquement ggplot2, mais je dois charger le paquet ggrepel. Je ne vais alors plus utiliser le geom_text mais à la place le geom_text_repel.
NB: pour les fonctionnalités de ce package
IMPRESSIONNANT!!!.
ggplot(data=veaux, mapping=aes(x=dehy, y=pulse, label=case))+ #ici je dois spécifier la variable dont je vais me servir pour afficher certaines donnés ou pas
geom_point(color = ifelse(veaux$case=="9805"|veaux$case=="4869"|veaux$case=="2926", "green", "red")) + #ici je cherche simplement les veaux dans ma BD et j'indique la couleur de ces cas spécifiques.
theme_classic()+
geom_text_repel(data=subset(veaux, case%in% c("9805", "4869", "2926")), mapping=aes(label=case)) #rappelez vous du signe %in% qui est équivalent variable case qui contient 9805, 4869 ou 2926...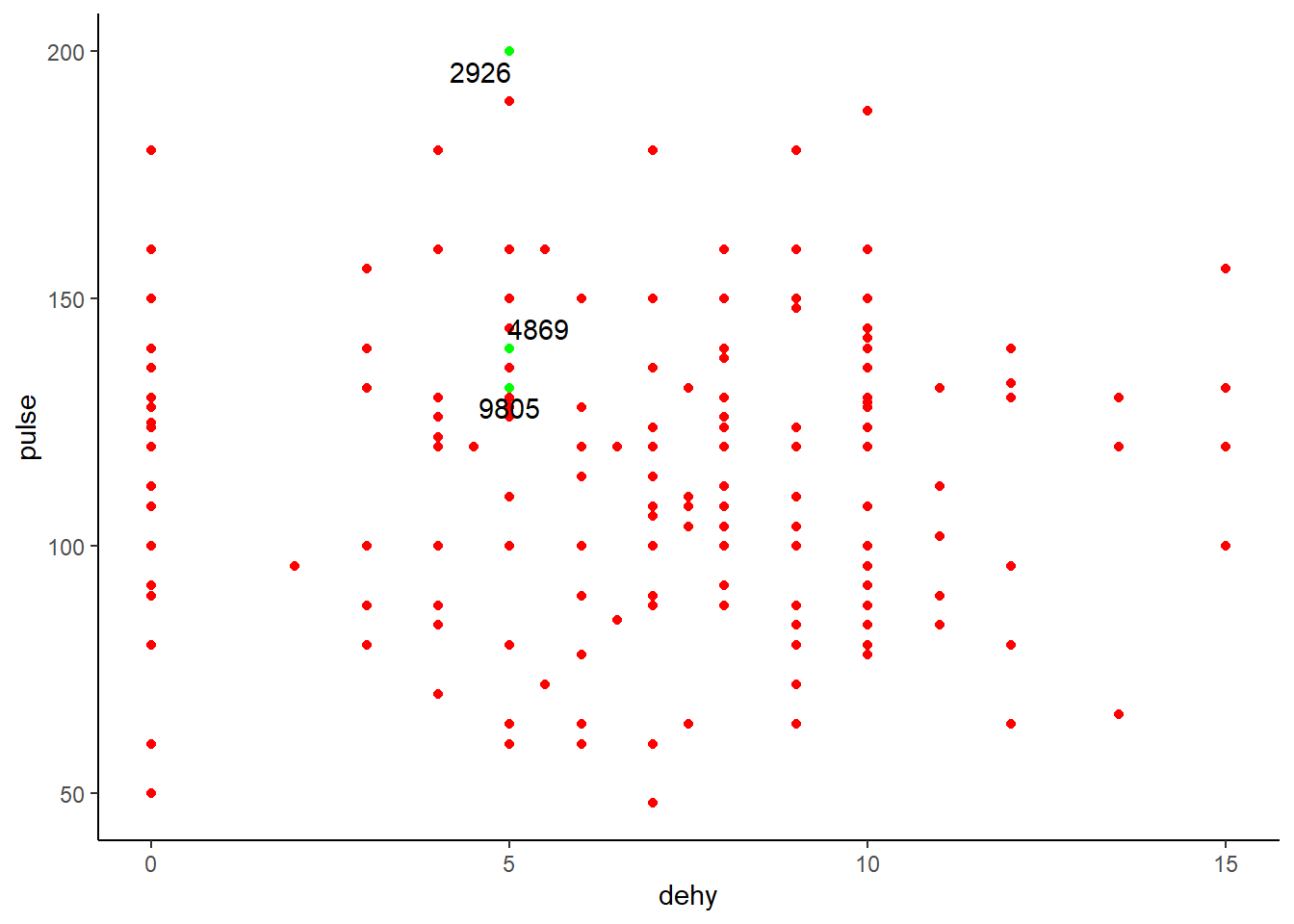
Bon je n’ai peut être pas pris le bon exemple de graph pour illustrer cet intérêt mais imaginez vous que j’aurai pu faire quelque chose de mieux visuellement… Si vous mettez par défaut d’afficher vos points cela risque de vous donner des maux de tête… (cf ci-dessous)
ggplot(data=veaux, mapping=aes(x=dehy, y=pulse, label=case))+
geom_point(color="red")+
geom_text_repel()+ # d'où l'intéret de spécifier quels points indiquer ou d'utiliser une figure avec moins de points...
ggtitle("Figure qui fait mal à la tête...")
6 Enregistrement de vos chefs d’oeuvres…
6.1 Enregistrer avec ggsave()
Une fois que vous êtes satisfait de vos graphiques, vous pouvez tout simplement les enregistrer soit individuellement soit en les ajoutants les uns aux autres.
ex1 <- g +geom_point(color="red") +
theme_bw() + labs(x="Déshydratation (%)", y="Fréquence cardiaque (bpm)") +
ggtitle("Figure à enregistrer")
ex1
ggsave("Ma figure.pdf") # je spécifie le nom d'enregistrement (ici Ma figure) ainsi que le format (ici pdf)
#admettons que je veuille lui accoler une 2ème figure
ex2 <- g + geom_smooth(color="yellow") +
theme_dark() + labs(x="Déshydratation (%)", y="Fréquence cardiaque (bpm)")
ex2
# je dois utiliser ggpubr()
library(ggpubr)
ggarrange(ex1, ex2, ncol=1)
ggsave("graphique_combiné.png")Et c’est tout… Notez bien sur que je peux spécifier la taille relative et la résolution que je souhaite bien sur…
Si vous voulez aller voir les infos sur ggpubr, vous verrez la puissance de ce paquet pour notamment utiliser des formats de graphiques prêts pour la publication. Allez voir sur ce site pour plus d’infos…
6.2 Spécifier le format
Il existe différents arguments poir spécifier la hauteur (height) et la largeur (width).
On va voir des exemples:
ex1
ggsave("F1.png")
**defaut 7.9*4.5**
ggsave("F2.png", height=4, width=3)
height 4, width 3
7. Autres extensions graphiques
Nous avons terminé avec ce tutoriel sur les fonctionnalités (une faible partie) de ggplot2. Vous pouvez maintenant je l’espère voler de vos propres ailes et faire de graphiques époustouflants. Vous verrez également que de nombreux packages d’analyses contiennent aussi des graphs que l’on peut modifier à volonté selon les principes de ggplot.
Bien sûr, il y a beaucoup d’autres packages qui se sont développés pour des graphiques plus spécifiques et qui fonctionnent comme:
corrplot qui gère la visualisation de corrélation selon les variables de votre BD

source: http://www.sthda.com/english/wiki/ggcorrplot-visualization-of-a-correlation-matrix-using-ggplot2
ggridges qui vous donnera des superpositions de densités époustouflants

avec gganimate vous pourrez rendre vos graphs encore plus vivant en les animant…

Ventes annuelles de veaux laitiers par encans S.Buczinski 2019

Bon le mieux est que je me taise et que je vous laisse juger par vous même toutes les possibilités. VOIR LES SITES:
Au final: R gagne haut la main devant excel (et même devant les autres logiciels de bases mais je suis un peu biaisé…)
=> en tout cas mon choix est fait!!!
MERCI!!!
Ce travail est un travail en progression, donc n’hésitez pas si il y a des coquilles ou problèmes à me les signaler pour que je les corrige s.buczinski@umontreal.ca
Sébastien Buczinski
Professeur titulaire clinique ambulatoire bovine
Ma recherche se focalise sur la santé des veaux, les maladies respiratoires bovines, les tests diagnostiques en l’absence de test de référence parfaits et la médecine vétérinaire factuelle.